
❐ Description
- 데이터베이스의 가장 기본적인 두 가지 동작
- 데이터 저장
- 데이터 제공
- 이번장에서는
- 데이터베이스가 데이터를 저장하는 방법과 데이터를 요청했을 때 다시 찾을 수 있는 방법에 대해 설명
- 익숙한 데이터베이스 종류인 RDB와 NoSQL에 사용되는 저장소 엔진에 대해 집중적으로 설명
- 로그 구조(log-structured) 계열 저장소(B-Tree) 엔진과 페이지 지향 계열 저장소 엔진도 살펴봄
- 특정 작업부하 유형에서 좋은 성능을 내게끔 저장소 엔진을 조정하려면
- 저장소 엔진이 내부엣버 수행되는 작업에 대해 대략적인 개념을 이해할 필요가 있음.
❐ 데이터베이스를 강력하게 만드는 데이터 구조
🌀 데이터베이스를 강력하게 만드는 데이터 구조
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
키-값 저장소를 함수 두 개로 구현
- db_set
- 데이터 저장
- 파일의 끝에 데이터를 추가하므로, 예전 버전을 덮어 쓰지 않음.
- 많은 데이터베이스는 내부적으로 append-only 데이터 파일인 로그(log)를 사용함
➔ 여기서 말하는 로그는 좀 일반적인 의미로, 연속된 추가 전용 레코드
➔ (원서) an append-only sequence of records.
-
- db_get
- 데이터 조회
- 데이터가 많으면 성능이 좋지 않음.
- 시간 복잡도 O(n)
- db_get
특정 키의 값을 효율적으로 찾기 위해서는? 색인(Index)가 필요함.
- 색인의 일반적인 개념은 어떤 부가적인 메타데이터를 유지하는 것.
- 많은 데이터베이스에서 색인(index)의 추가와 삭제를 허용함
- 색인은 탐색 성능에 도움이 됨.
- 하지만 쓰기 성능 에서는 매번 색인도 갱신해야 해서 오버헤드 발생
- 따라서 읽기/쓰기 트레이드오프가 존재
- 개발자들이 수동으로 색인을 잘 선택해야 함.
🌀 해시 색인
해시 색인
- 키-값 저장소는 사전(dictionary) 타입과 매우 유사
- 보통 hash-map으로 구현
가장 간단한 해시 색인 전략

- 단순해보이지만, 많이 사용하는 접근법.
- 이 방식은 "비트캐스크"가 근본적으로 사용하는 방식
저장소 엔진 - 비트캐스크
- 해시 맵을 전부 메모리에 유지
- 따라서, 사용 가능한 RAM에 모든 키가 저장된다는 전제를 깔고 감.
- 이로써, 고성능으로 읽기 쓰기를 보장함
- 값은 한 번의 디스크 탐색으로 적재할 수 있음.
- 따라서, 사용 가능한 메모리보다 더 많은 공간을 사용할 수 있음.
- 데이터 파일의 일부가 이미 파일 시스템 캐시에 있는 상황이라면?
- 읽기 작업에 디스크 입출력이 필요하지 않음.
- 비트캐스크가 서버 재시작할 때, 복구 속도를 높이는 방법
- 각 세그먼트 해시 맵을 메모리로 조금 더 빠르게 로딩할 수 있게 스냅숏을 디스크에 저장
- 언제 적합한가?
- 각 키의 값이 자주 갱신되는 상황
- Ex) 키는 어떤 비디오의 URL, 값은 비디오 재생횟수
계속 추가만 하게되면 디스크 공간이 부족해지는데.. 이를 어떻게 해결할까?
- 특정 크기의 세그먼트로 로그를 나누기 & 컴팩션(compaction)
컴팩션

- 컴팩션이란?
- 로그에서 중복된 키를 버리고 각 키의 최신 갱신 값만 유지 하는 것.
- 컴팩션은 보통 세그먼트를 작게 만듬.
- 따라서, 컴팩션을 수행할 때 동시에 여러 세그먼트들을 병합할 수 있음.
- 세그먼트가 쓰여진 후에는 절대로 변경할 수 없음.
- 따라서, 병합할 세그먼트는 새로운 파일로 만듬
- 컴팩션 & 병합을 수행하는 동안...
- 고정된 세그먼트의 병합과 컴팩션은 백그라운드 스레드에서 수행할 수 있음.
- 이전 세그먼트 파일을 사용해 읽기와 쓰기 요청을 처리함.
- 병합 과정이 끝난 이후에는 읽기 요청은 새로운 세그먼트를 사용
- 전환 후 이전 세그먼트 파일은 삭제
- 앞선 과정을 통해, 조회할 때는 많은 해시 맵을 확인할 필요가 없다.
- 실제 구현해서 고려해야 할 점
- 파일 형식
- 레코드 삭제
- 고장(crash) 복구
- 부분적으로 레코드 쓰기
- 동시성 제어
Append-only 설계는 여러 측면에서 좋은 설계다.
- 쓰기 성능
- 추가와 세그먼트 병합은 순차적인 쓰기 작업.
- 따라서 무작위 쓰기 보다 훨씬 빠름
- 동시성 고장 복구
- 세그먼트 파일이 append-only거나 불변이면 훨씬 간단
- 조각화 방지
- 오래된 세그먼트 병합은 시간이 지남에 따라 조각화되는 데이터 파일 문제를 피할 수 있음.
해시 테이블 색인의 제한 사항
- 키가 너무 많은 경우
- 디스크 상의 해시맵에 좋은 성능을 기대하긴 힘듬.
- 무작위 접근 I/O가 많이 필요함
- 디스크가 가득 찼을 때 확장하는 비용이 비쌈
- 해시 충돌 해소를 위해 성가신 로직이 필요함
- 디스크 상의 해시맵에 좋은 성능을 기대하긴 힘듬.
- 범위 질의
- 해시 테이블은 범위 질의에 효과적이지 않음.
🌀 SS테이블과 LSM 트리
Sorted String(SS) 테이블이란?
- 기존 log-structured 세그먼트을 키로 정렬한 형식
- 해시 색인을 가진 log-structured 세그먼트보다 몇 가지 장점을 가짐
해시 색인 보다 나은 점 3개
- 효율적인 세그먼트 병합
- 효율적인 색인 관리
- 읽기 성능 향상(범위 탐색) & 디스크 공간 절약
SS테이블 생성과 유지
- 디스크 상에 정렬된 구조를 유지하는 것 가능은 함.
- 하지만 메모리에 유지하는 편이 훨씬 쉬움.
- 트리 데이터 구조(RB, AVL)를 이용하면 임의 순서로 키를 삽입하고 정렬된 순서로 다시 읽을 수 있음.
SS테이블에서 LSM 트리 만들기
- LSM(Log-Structured Merge) 저장소 엔진이란?
- 정렬된 파일 병합과 컴팩션 원리를 기반으로 하는 저장소 엔진
- 기본 개념
- 백그라운드에서 연쇄적으로 SS 테이블을 지속적으로 병합하는 것
- 이 개념은 데이터셋이 가능한 메모리보다 훨씬 더 크더라도, 여전히 효과적
- 데이터가 정렬된 순서로 저장돼 있다면 범위 질의를 효율적으로 실행할 수 있음.
- 이 접근의 디스크 쓰기는 순차적이기 때문에 LSM 트리가 매우 높은 쓰기 처리량을 보장
성능 최적화
- LSM 트리 알고리즘은 데이터베이스에 존재하지 않는 키를 찾는 경우 느릴 수 있음.
- 멤테이블을 확인한 다음 키가 존재하지 않는 다는 사실을 확인하기 전까진
가장 오래된 세그먼트까지 거슬러 올라가야 하기 때문
- 멤테이블을 확인한 다음 키가 존재하지 않는 다는 사실을 확인하기 전까진
- 이런 방식을 최적화하기 위해 저장소 엔진은 보통 블룸 필터(Bloom filter)를 추가적으로 사용
- Bloom filter란?
- (원서) memory-efficient data structure for approximating the contents of a set
- 집합을 정확하게 다 저장하지 않고(메모리 절약), 약간의 오차를 허용하면서
특정 집합에 특정 요소의 존재 여부를 근사적으로 판단할 수 있는 자료구조 - 키가 데이터베이스에 존재하지 않음을 알려주므로
존재하지 않는 키를 위한 불필요한 디스크 읽기를 많이 절약할 수 있음.
- SS 테이블을 압축하고 병합하는 순서와 시기를 결정하는 다양한 전략
- 크기 계층(size-tiered) 컴팩션
- HBase, 카산드라
- 상대적으로 좀 더 새롭고 작은 SS테이블을 상대적으로 오래됐고 큰 SS테이블에 연이어 병합
- 레벨(level) 컴팩션
- 레벨DB, 록스DB, 카산드라
- 키 범위를 더 작은 SS테이블로 나눔
- 오래된 데이터는 개별 "래벨"로 이동하기 때문에 컴팩션을 점진적으로 진행해 디스크 공간 절약
- 크기 계층(size-tiered) 컴팩션
🌀 B 트리
B 트리
- 가장 널리 사용되는 색인 구조
- 거의 대부분의 관계형 데이터베이스에서 표준 색인 구현으로 사용(비관계혀에서도 사용됨)
- log-structured 색인과는 상당히 다름
- SS테이블과 같이 키로 정렬된 k-v 쌍을 유지하기 때문에 범위 질의에 효율적
설계 철학
- 4KB 이상의 고정 크기 블록이나 페이지로 나누고 한 번에 하나의 페이지에 읽기 또는 쓰기를 함
- 디스크가 고정 크기 블록으로 배열되기 때문에 이런 설계는 근본적으로 하드웨어와 더 밀접함
- 각 페이지는 주소나 위치를 이용해 식별할 수 있음

- 이 방식으로 하나의 페이지가 다른 페이지를 참조할 수 있음.
- 포인터와 비슷하지만 메모리 대신 디스크에 있음.
- 한 페이지는 B트리의 root로 지정
- 색인에서 키를 찾으려면 루트에서 시작
- 페이지는 여러 키와 하위 페이지의 참조를 포함
- 각 하위 페이지는 키가 계속 이어지는 범위를 담당하고 참조 사이의 키는 해당 범위 경계를 나타냄
- 최종적으로 개별 키(리프 페이지)를 포함하는 페이지에 도달
- 분기 계수(branching factor)
- B 트리의 한 페이지에서 하위 페이지를 참조하는 수
- 위 이미지의 분기 계수는 6
- B 트리에 존재하는 키의 값을 갱신하려면?
- 키를 포함하고 있는 리프 페이지 검색
- 페이지의 값 갱신 후 디스크에 다시 기록
- 새로운 키를 추가하려면
- 새로운 키를 포함하는 범위의 페이지를 찾아 해당 페이지에 키와 값을 추가
- 새로운 키를 수용할 페이지에 충분한 여유 공간이 없다면

- 페이지 하나를 반쯤 채워진 페이지 둘로 나누고
- 상위 페이지가 새로운 키 범위의 하위 부분들을 알 수 있게 갱신
- 앞서 본 알고리즘은 트리가 계속 균형을 유지하는 것을 보장
- n개의 키를 가진 B 트리는 깊이가 항상 OlogN
신뢰할 수 있는 B 트리 만들기
- B 트리의 기본적인 쓰기 동작은 새로운 데이터를 디스크 상의 페이지에 덮어쓰는 것.
- 이 동작은 덮어쓰기가 페이지 위치를 변경하지 않는다고 가정
- 따라서 페이지를 가르키는 모든 참조는 온전히 유지
- 디스크의 페이지를 덮어쓰는 일은 실제 하드웨어 동작이라고 볼 수 있음.
- 고아페이지가 생기는 문제, 동시성 문제...
- 그래서 신뢰할 수 있는 B트리는 어떻게 만드냐
- 데이터베이스가 고장상황에서 스스로 복구할 수 있게 만들어야 함.
- 디스크 상에 write-ahead log(WAL), redo log 라고 하는 데이터 구조를 추가해서 B 트리 구현
- 동시성 제어 - latch(가변운 lock)로 트리의 데이터 구조를 보호
B 트리 최적화 기법
- WAL 유지 대신, 일부 데이터베이스는 쓰기 시 복사 방식(copy-on-write-scheme)을 사용
- 동시성 제어에도 유리함 (236쪽 "스냅숏 격리와 반복 읽기")
- 키를 축약해서 공간 절약
- 트리 내부 페이지에서 키가 키 범위 사이의 경계 역할을 하는데 충분한 정보만 제공하면 됨.
- 리프 페이지를 디스크 상에 연속된 순서로 나타나게끔 트리를 배치하려고 시도
- 트리가 터지면 순서를 유지하기 힘듬
- 트리에 포인터 추가
- 예를 들면 각 리프 페이지가 양쪽 형제 페이지에 대한 참조를 가지는 것
- 프랙탈 트리같은 B 트리 변형은 디스크 찾기를 줄이기 위해 로그 구조화 개념을 일부 빌림.
🌀 B 트리와 LSM 트리 비교
| B tree | LSM | |
| 쓰기 성능 | ✅ | |
| 읽기 성능 | ✅ |
- LSM 읽기가 더 느린 이유
- 각 컴팩션 단계에 있는 여러 가지 데이터 구조와 SS테이블을 확인해야 하기 때문
LSM 트리의 장점
- 쓰기 증폭이 낮음
- B 트리는 모든 데이터 조각을 최소 두 번 기록해야 함.(로그 + 페이지 전체 기록)
➔ 같은 페이지를 여러 번 쓰는 오버헤드 - LSM 트리는 여러 번 덮어쓰지 않고, 순차적으로만 쓰고 주기적으로 병합(compaction)
- B 트리는 모든 데이터 조각을 최소 두 번 기록해야 함.(로그 + 페이지 전체 기록)
- 쓰기 처리량을 높게 유지할 수 있음.
- LSM이 상대적으로 쓰기 증폭이 낮고
- 순차적으로 컴팩션된 SS 테이블 파일을 쓰기 때문
- 압축률이 좋음
- B 트리 저장소 엔진은 파편화로 인해 사용하지 않는 디스크 공간 일부가 남음
- 반면에 LSM 트리는 주기적으로 파편화를 없애기 위해, SS테이블을 다시 기록
- 레벨 컴팩션을 사용하면 더 좋음
LSM 트리의 단점
- 컴팩션 과정
- 때로는 진행 중인 읽기와 쓰기 성능에 영향을 줌.
- 디스크가 가진 자원은 한계가 있고, 그로 인해 비싼 컴팩션 연산이 끝날때 까지 대기해야 하는 상황 발생
- 높은 쓰기 처리량
- 디스크의 쓰기 대역폭은 유한한데,
- 초기 쓰기(로그, 멤테이블 flush)와 백그라운드 컴팩션(compaction)이 디스크 I/O 대역폭을 공유
- 쓰기 처리량이 높음에도 컴팩션 설정을 주의 깊게 하지 않으면 컴팩션이 유입 쓰기 속도를 따라갈 수 없음
- 이 경우 디스크 상에 병합되지 않은 세그먼트 수는 디스크 공간이 부족할 때 까지 증가함
- 그리고 더 많은 세그먼트 파일을 확인해야 하기 때문에 읽기 또한 느려짐
- 다중 복사본의 존재 가능성
- B 트리는 각 키가 색인 한 곳에만 정확하게 존재
- 반면 log-structured 저장소 엔진은 다른 세그먼트에 같은 키의 다중 복사본이 존재할 수 있음.
🌀 기타 색인 구조
보조 색인 (Secondary index)
- RDB에서는 CREATE INDEX 명령을 사용해서 보조 색인을 생성할 수 잇음.
- 보통 효율적으로 조인을 수행하는 데 결정적인 역할을 함.
- 기본키 색인과의 주요 차이점은 키가 고유하지 않다는 점
- 위 문제를 해결하는 두 가지 방식
- 색인의 각 키에 대해 일치하는 로우 식별자(row ID)들의 목록을 저장.
- 복합 키 방식 : "로우 식별자" 조합으로 키를 고유하게 만듦.
- 위 문제를 해결하는 두 가지 방식
색인 안에 값 저장하기
- 색인에서
- 키는 질의가 검색하는 대상
- 값은
- 질문의 실제 로우(문서, 정점)
- (다른 곳에 저장된 로우를 가리키는) 참조
- 로우가 저장된 곳을 힙 파일(heap file)이라고 함.
- 특정 순서 없이 데이터를 저장함.
- 힙 파일 접근 방식
- 일반적인 방식
- 여로 보조 색인이 존재할 때 데이터 중복을 피할 수 있음.
- 각 색인은 힙 파일에 위치만 참고하고 실제 데이터는 일정한 곳에 유지
- 이 방식은 키를 변경하지 않고 값을 갱신할 때 효율적
- 새로운 값이 많은 공간을 필요로 한다면?
- 힙에서 충분한 공간이 있는 새로운 곳으로 위치를 이동해야 함
- 이런 경우 모든 색인이 레코드의 새로운 힘 위치를 가리키게 끔 갱신
- 또는 이전 힙 위치에 전방향 포인터를 남겨둬야 한다.
- 색인에서 힙 파일로 다시 이동하는 일은 읽기 성능에 큰 불이익
- 클러스터 색인
- 색인 안에 바로 색인된 로우를 저장하는 방식
- MySQL의 InnoDB 엔진에서는 테이블의 기본키가 언제나 클러스터드 색인이고
보조 색인은 기본키를 참조
- 커버링 인덱스 (index with included column)
- 클러스터드 인덱스와 비클러스터드 인덱스의 절충안
- 색인 안에 테이블의 컬럼 일부를 저장
- 이렇게 하면 색인만 사용해 일부 질의에 응답이 가능
이런 경우 인덱스가 색인의 질의를 커버했다고 말함.
클러스터드 색인과 커버링 색인은 읽기 성능을 높일 수 있지만 추가적인 저장소가 필요하고
쓰기 과정에 오버헤드가 발생함. 또한 애플리케이션 단에서 복제로 인한 불일치를 파악할 수
없기 때문에 데이터베이스는 트랜잭션 보장을 강화하기 위해 별도의 노력이 필요.
다중 컬럼 색인
- 결합 색인 (Concatenated index)
- 하나의 컬럼에 다른 컬럼을 추가하는 방식으로 하나의 키에 여러 필드를 단순히 결합하는 방식
- (성, 이름)을 키로 전화번호를 값으로 하는 색인을 제공하는 구식 종이 전화번호부와 유사
- 다차원 색인
- 한 번에 여러 컬럼에 질의하는 조금 더 일반적인 방법
- 특히 지리 공간 데이터에 중요하게 사용됨
전문(Full-text) 검색과 퍼지(fuzzy) 색인
- 지금까지 살펴본 색인은
- 정확한 데이터를 대상으로 키의 정확한 값이나
- 정렬된 키의 값의 범위를 질의할 수 있다고 가정
- 즉, 유사한 키에 대해서는 검색할 수 없음.
- 애매모호(fuzzy)한 질의에는 다른 기술이 필요
- "루씬"은 문서나 질의의 오타에 대처하기 위해 특정 편집 거리 내 단어를 검색할 수 있음.
모든 것을 메모리에 보관 (인메모리)
- 지금까지 설명한 데이터 구조는 모두 디스크 한계에 대한 해결책
- 디스크의 장점
- 지속성 → 전원이 꺼져도 데이터가 유지됨.
- 저렴한 비용 → 기가바이트당 가격이 메모리보다 훨씬 저렴.
- 인메모리 데이터 베이스가 개발된 이유는?
- 램 가격 하락 + 데이터셋 크기가 그리 크지 않음. 즉, 메모리에 전체 보관 가능.
- 또는 여러 장비에 분산 저장 가능.
- 맴캐시드 & 그 외 인메모리DB
- 맴캐시드 → 데이터 손실 허용
- 그 외 → 지속성을 목표로 함(데이터 손실 허용X)
- 어떻게?
- 특수 하드웨어 사용
- 디스크에 변경 사항의 로그를 기록
- 디스크에 주기적인 스냅숏을 기록
- 다른 장비에 인메모리 상태를 복제
- 어떻게?
- 디스크 기반 색인으로 구현하기 어려운 데이터 모델을 제공
- 레디스 → 우선순위 큐와 셋(set) 같은 다양한 데이터 구조를 인터페이스로 제공
- 메모리에 모든 데이터를 유지하기 때문에 구현이 비교적 간단
- 최근 연구에 따르면 인메모리 DB 아키텍쳐는 가용한 메모리보다 더 큰 데이터셋을 지원하게 끔 확장 가능
- 안티 캐싱 접근 방식
- 메모리가 충분하지 않을 때 가장 최근에 사용하지 않은 데이터를 메모리에서 디스크로 내보냄
- 그리고 나중에 다시 접근할 때, 메모리에 적재하는 방식으로 동작
- 안티 캐싱 접근 방식
- 비휘발성 메모리 (NVM) 기술이 더 널리 채택되면 저장소 엔진 설계의 변경이 필요할 것임
❐ 트랜잭션 처리나 분석? (Transaction Processing or Analytics?)
🌀 과거와 현재의 트랜잭션 의미
- 과거(초기)의 데이터베이스 쓰기는
- 주로 판매, 공급업체에 발주, 직원 급여 지급 같은
- 커머셜 트랜잭션(commercial transaction, 상거래) 에 해당했음.
- 하지만 현재는
- 트랜잭션이라는 용어는 변하지 않음.
- 데이터베이스에서는 논리적 단위(logical unit)의 읽기와 쓰기 그룹을 의미.
🌀 OLTP & OLAP
OLTP - Online transaction processing
- 보통 애플리케이션은 색인을 사용해 레코드를 찾음
- 레코드는 사용자 입력을 기반으로 삽입 또는 갱신
- 이런 애플리케이션은 대화식이기 때문에 이 접근 패턴을 OLTP라고 함.
OLAP - Online analytic processing
- DB를 데이터 분석에도 점점 더 많이 사용하기 시작함
- 보통 분석 질의는 사용자에게 원시 테이터를 반환하는 것이 아님
- 많은 수의 레코드를 스캔해 레코드당 일부 컬럼만 읽어 집계 통계를 계산한 데이터를 반환함.
- 이런 DB 사용 패턴을 트랜잭션 처리와 구별하기 위해 OLAP라고 함.
OLTP와 OLAP의 특징 비교

🌀 데이터 웨어하우징
데이터 웨어하우스(data warehouse)란?
- 트랜잭션 처리용 OLTP 시스템과는 별도로, 분석을 목적으로 운영 데이터와 이력을 모아두는 개별 데이터베이스
데이터 웨어하우스 왜 등장함?
- 기본적으로 OLTP 시스템은 사업 운영에 굉장히 중요함
- 따라서, 높은 가용성(HA)과 낮은 지연 시간의 트랜잭션 처리를 기대함
- 근데 여기다가 비즈니스 분석가가 분석 질의를 날리면?
- 분석 질의는 대개 비용이 비싸서 OLTP 성능을 저하시킬 수 있음.
- 그래서 분석 전용 데이터베이스가 나옴
- 그게 데이터 웨어하우스. (OLTP 데이터베이스의 읽기 전용 복사본)
- 분석가들이 OLTP 작업에 영향을 주지 않고 마음껏 질의 가능
- 데이터는 OLTP 데이터베이스에서 주기적으로 ETL(Extract-Transform-Load) 과정을 거쳐 가져옴

데이터 웨어하우스 사용 실태
- 모든 대기업에는 데이터 웨어하우스가 있지만, 소규모 기업은 그렇지 않음.
- 데이터 양이 차이가 나기 때문
- 적은 양의 데이터를 가지는 소규모 기업의 경우, 걍 OLTP에 질의 해도 큰 문제 없음.
OLTP 데이터베이스와 데이터 웨어하우스의 차이점
- 표면적으로 데이터 웨어하우스와 관계형 OLTP 데이터베이스는 비슷해 보임
- 둘 다 SQL 질의 인터페이스를 지원하기 때문
- 하지만 각각 매우 다른 질의 패턴에 맞게 최적화됐기 때문에 시스템 내부는 완전 다름
- 위에 OLPT & OLAP 차이
🌀 분석용 스키마 : "별 모양 스키마"와 "눈꽃송이 모양 스키마" (Star & Snowflakes)
차원 모델링
- 많은 데이터 웨어하우스가 사용하는 정형화된 방식
- 대표적으로
- 별 모양 (star)
- 눈 꽃송이 모양 (snowflakes)
별 모양 - 많은 데이터 웨어하우스가 사용하는 모델

- "사실 테이블"을 중심으로 여러 차원 테이블이 직접 연결된 구조.
- 사실 테이블 : fact_sales
- 차원 테이블 : dim_products, dim_store, dim_date, dim_customer, dim_promotion
- 사실 테이블의 각 로우는 개별 이벤트를 나타냄.
- 나중에 분석의 유연성을 극대화할 수 있기 때문임
- 반대로, 사실 테이블이 커질 수 있다는 의미
- 차원은 이벤트의 속성인
- "누가, 언제, 어디서, 무엇을, 어떻게, 왜" 를 나타냄
눈꽃송이 모양
- 별 모양의 변형
- 차원이 하위차원으로 더 세분화 됨.
- 예를 들면
- 브랜드(brand)와 제품 범주(category)의 테이블을 분리할 수 있음.
- dim_product 테이블의 각 로우는 외래 키로 참조할 수 있음.
❐ 컬럼 지향 저장소
🌀 컬럼 지향 저장소
아이디어
- 모든 값을 하나의 로우에 저장하지 않고, 컬럼에 저장하자!
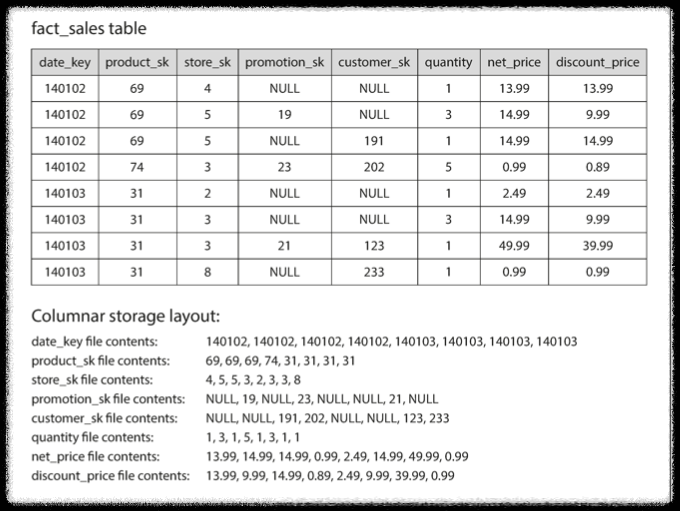
- column-oriented 저장소의 layout : 각 컬럼 파일 안의 row의 순서는 서로 일치
🌀 컬럼 압축
- 질의에 필요한 데이터를 디스크에서 읽는 작업 외에도 데이터를 압축하면 디스크 throughput을 더 줄일 수 있음.
- 다행히도 column-oriented 저장소는 컬럼 압축에 적합함.

- 딱 봐도 반복이 많이 보임 → 압축을 하기에 좋은 신호(sign)
- 데이터에 따라 다른 압축 기법이 사용됨.
비트맵 부호화 (Bitmap encoding)
- 여러 압축 기법중 하나로, 데이터 웨어하우스에서 특히 효과적
- 컬럼에 들어있는 값들은 보통 중복이 많고 고유 값의 개수는 적음.
- n개의 고유 값을 가진 컬럼을 가져와, n개의 비트 맵을 만들 수 있음.
- 고유 값 하나 당 비트맵 한 개
- 각 비트 맵은 로우 수 만큼 비트를 가짐
- 로우가 해당 값을 가지면 비트는 1 (아니면 0)
- n개의 고유 값을 가진 컬럼을 가져와, n개의 비트 맵을 만들 수 있음.
- n이 매우 작으면, 이 비트맵은 로우당 하나의 비트로 저장할 수 있음.
- n이 크면, 비트맵은 0이 더 많아 낭비가 심함
- 이런 경우를 희소(sparse)라고 함.
- 런-랭스 인코딩(run-length encoding, 같은 값이 연속되면 압축) 같은 방식을 적용
- This can make the "encoding of a column" remarkably compact
메모리 대역폭과 벡터화 처리
- 데이터 웨어하우스는
- 디스크로부터 메모리로 데이터를 가져오는 대역폭이 큰 병목
- 메모리에서 CPU cache로 데이터를 가져올 때도 병목이 생김.
- colum-oriented 저장소 레이아웃은 CPU cycle을 효율적으로 사용하기에 적합함.
- 질의 엔진은 압축된 칼럼 데이터를 CPU의 L1 캐시에 딱 맞게 덩어리로 나누어 가져오고
- 이 작업을 (함수 호출이 없는) 타이트 루프(tight loop)에서 반복함
- CPU는 code 보다 타이트 루프를 빨리 실행할 수 있음
- 여기서 말하는 특정 코드는
- 레코드 처리를 위해 많은 function call이나 분기가 필요한 코드를 말함
- 컬럼 압축을 사용하면 같은 양의 L1 캐시에 컬럼의 더 많은 로우를 저장할 수 있음.
- 벡터화 처리(Vectorized Processing)
- 비트 연산자(AND, OR 등)는 압축된 컬럼 데이터 블록에 직접 적용할 수 있다.
- 즉, 데이터 덩어리를 벡터 단위로 연산하는 방식이 가능하다.
- 이를 벡터화 처리(vectorized processing) 라고 함.
🌀 컬럼 저장소의 순서 정렬
컬럼 저장소와 순서
- 컬럼 저장소에서 로우가 저장된느 순서가 반드시 중요하지는 않음.
- 삽입된 순서로 저장하는 방식이 가장 단순
- 순서를 도입하면, 이를 색인 메커니즘처럼 사용할 수 있음.
- 각 컬럼을 독립적으로 정렬할 수는 없음.
- 그렇게 하면 더 이상 칼럼의 어떤 항목이 동일한 로우에 속하는지 알 수 없기 때문
- 따라서 테이블 전체를 기준으로 특정 칼럼을 정렬 키(sort key) 로 선택해야 함.
- 예: date_key 기준으로 정렬 → "지난 달" 같은 범위 질의가 훨씬 빨라짐.
다중정렬
- 첫 번째 컬럼으로 정렬한 뒤, 같은 값들을 두 번째 칼럼 기준으로 정렬 가능.
- date_key → product_sk 순으로 정렬하면
- 특정 날짜에 팔린 상품을 효율적으로 그룹화/필터링 가능.
장점
- 컬럼 압축에 도움이 됨.
- 기본 정렬 컬럼에 고유 값을 많이 포함하지 않는다면
- 정렬 이후, 연속해서 같은 값이 길게 반복됨.
- 이런 압출 효과는 첫 번째 정렬 키에서 가장 강력함.
다양한 순서 정렬
- 복제 데이터를 서로 다른 방식으로 정렬해서 저장하면
- 질의를 처리할 때 질의 패턴에 가장 적합한 버전을 사용할 수 있음.
- 컬럼 지향 저장에서 여러 정렬 순서를 갖는 것은
- 로우 지향 저장에서 여러 2차 색인을 갖는 것과 약간 비슷
- 하지만 로우 지향 저장은 한 곳에 모든 로우를 유지하고
- 2차 색인은 일치하는 로우를 가리키는 포인터만 포함함
- 컬럼 저장에서는, 단지 값을 포함한 컬럼만 존재함.
- 로우 지향 저장에서 여러 2차 색인을 갖는 것과 약간 비슷
🌀 컬럼 지향 저장소에 쓰기
- 컬럼 지향 저장소, 압축, 정렬은 모두 읽기 질의를 빠르게 함.
- 하지만 쓰기를 어렵게 한다는 단점을 갖고 있음.
- 다행히도 LSM 트리라는 좋은 해결책이 있음.
- 모든 쓰기는 먼저 인메모리 저장소로 이동해 정렬된 구조에 추가하고 디스크에 쓸 준비를 함.
- 인메모리 저장소가 로우 지향인지 컬럼 지향인진 알필요 없음.
- 충분한 쓰기를 모으면 디스크의 컬럼 파일에 병합하고 대량으로 새로운 파일에 기록함
🌀 집계: 데이터 큐브와 구체화 뷰
구체화 집계(materialized aggregate)
- 아이디어 : 질의가 자주 사용하는 일부 count나 sum을 캐시하는건 어떨까?
- 구체화 뷰(materialized view)를 통해서 캐시를 만들 수 있음!
구체화 뷰
- 관계형 데이터 모델에서는 이런 캐시를 만드는 방법 중 하나
- 구체화 뷰는 원본 데이터의 비정규화된 복사본으로, 원본 데이터를 변경하면 구체화 뷰를 갱신해야 함.
- 하지만, 갱신으로 인한 쓰기 비용이 비싸기 때문에 OLTP 데이터베이스에서는 구체화 뷰를 자주 사용하지 않음.
- 데이터 웨어하우스는 읽기 비중이 크기 때문에 구체화 뷰를 사용하는 전략은 합리적임.
데이터 큐브(data cube, OLAP 큐브)
- 일반화된 구체화 뷰의 특별 사례

- 한 축은 date, 다른 한 축은 product
- date와 product인 2차원 테이블을 그릴 수 있음.
- 각 셀은 날짜와 제품을 결합한 모든 사실의 속성(net_price)의 집계(sum) 값을 포함함.
- 장점
- 특정 질의를 효과적으로 미리 계산했기 때문에 해당 질의를 수행할 때 매우 빠름
- 단점
- 원시 데이터에 질의하는 것과 동이한 유연성이 없음.
표준(가상) 뷰 란?
- 몇몇 질의 결과가 contents인 table-like object
- 가상 뷰에서 읽을 때 SQL 엔진은 뷰의 원래 질의로 즉석에서 확장하고 나서 질의를 처리함.
the SQL engine expands it into the
view’s underlying query on the fly and then processes the expanded query.
구체화 뷰와 표준(가상) 뷰의 차이점
- 구체화 뷰는 디스크에 기록된 질의 결과의 실제 복사본
- 가상 뷰는 단지 질의를 작성하는 단축키
❐ 정리
- 데이터베이스가 어떻게 저장과 검색을 다루는지 근본적인 내용을 알아봄
- 고수준에서 저장소 엔진은 OLTP, OLAP 두 가지 범주로 나뉨
- 로그 구조화 저장소 엔진은 비교적 최근에 개발됐음.
- 핵심 아이디어는 임의 접근 쓰기를 체계적으로 디스크에 순차 쓰기로 바꾼 것.
- 컬럼 지향 저장소가 어떻게 아래 목표를 달성하는지 알아봄
- 질의가 디스크에서 읽는 데이터의 양을 최소화하는 법
'Book > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| 5장. 복제 (0) | 2025.09.14 |
|---|---|
| Part2. 분산 데이터 (0) | 2025.09.13 |
| 4장. 부호화와 발전 (Encoding & Evolution) (0) | 2025.09.06 |
| 2장. 데이터 모델과 질의 언어 (0) | 2025.08.23 |
| 1장. 신뢰할 수 있고 확장 가능하며 유지보수하기 쉬운 애플리케이션 (0) | 2025.08.16 |