
❐ Description
- 오늘날 많은 애플리케이션은 데이터 중심적(data-intensive)
- 데이터 중심 애플리케이션 표준 구성 요소(standard building block)로 만듬
- 데이터베이스
- 캐시
- 검색 색인 (Search Index)
- 스트림 처리 (Stream processing)
- 일괄 처리 (Batch processing)
- 이 책은
- 데이터 시스템의 원칙(principal)
- 실용성(practicality)
- 이를 활용한 데이터 중심 애플리케이션을 개발하는 방법을 담고 있음.
❐ 데이터 시스템에 대한 생각
왜 데이터 시스템이라는 포괄적 용어로 묶어야 하나?
- 경계의 모호성
- 최근에 다양한 새로운 도구들이 등장. 이 도구들은 다양한 사용 사례(Use Case)에 최적화
- 따라서, 전통적인 분류(=DB, 메시지큐, 캐시 등)로 딱 맞게 구분하기 어려움
- Ex) Kafka는 메시지큐지만 데이터베이스처럼 지속성(durability) 을 보장
- 단일 도구로는 처리할 수 없는 광범위한 요구사항
- 일을 여러 작업 단위(Task)로 세분화
- 각 작업은 그에 최적화된 도구(캐시, 검색 서버, 메시지 큐 등)를 사용해 처리
➔ 결국 애플리케이션은 다양한 도구들을 코드로 엮어서 협력하게 만드는 역할을 하게됨.
다양한 구성 요소를 결합한 데이터 시스템 아키텍처의 예
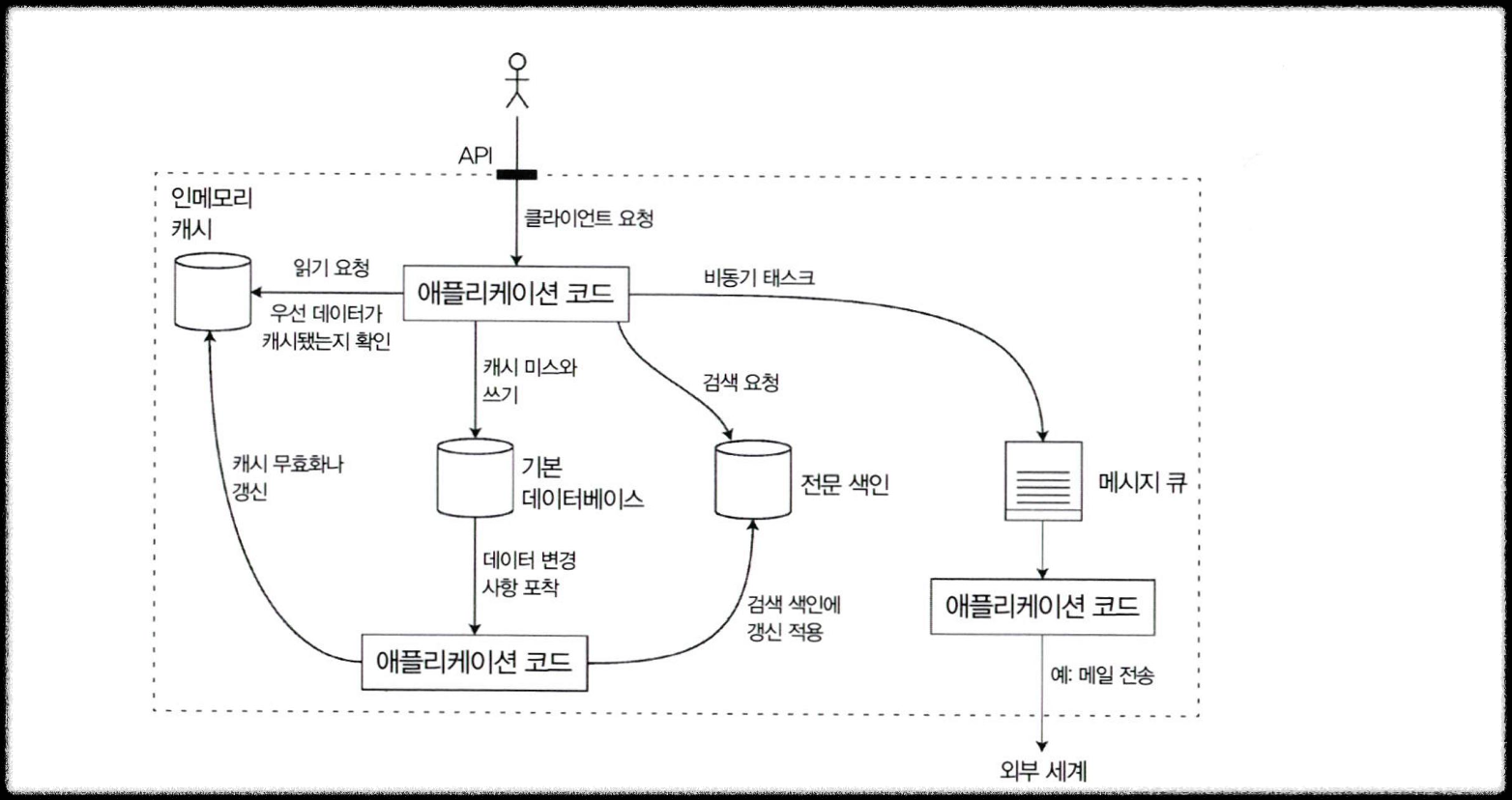
- 사용자가 API 요청을 보냄 → 애플리케이션 코드가 받음.
- 캐시 확인
- 캐시에 데이터 있으면 바로 응답.
- 없으면(DB 미스) DB에서 가져오고, 그 결과를 캐시에 저장.
- 검색 요청
- 검색이 필요한 경우, 전문 검색 엔진(예: Elasticsearch)에 요청.
- DB 변경이 발생하면, 검색 엔진에도 갱신이 적용되도록 동기화.
- 비동기 작업
- 메일 전송 같은 작업은 메시지 큐에 넣고, 애플리케이션이 따로 처리.
이 책의 중점을 둔 세 가지 관심사
- 신뢰성 (Reliability)
- 하드웨어나 소프트웨어 결함, 심지어 인적 오류 같은 역경에 직면하더라도,
- 시스템은 지속적으로 올바르게 동작(원하는 성능 수준에서 정확한 기능 수행)해야 함
- 확정성 (Scalability)
- 시스템의 데이터 양, 트래픽 양, 복잡도 증가하면서 이를 처리할 수 있는 방법이 있어야 함.
- 유지보수성 (Maintainability)
- 시간이 지남에 따라 다양한 사람들이 작업을 하게 됨.
- 따라서 모든 사용자가 시스템 상에서 생산적으로 작업할 수 있게 해야 함.
❐ 신뢰성
소프트웨어의 경우 일반적인 신뢰에 대한 기대치
- 애플리케이션은 사용자가 기대한 기능을 수행한다.
- 시스템은 사용자가 범한 실수나 예상치 못한 소프트웨어 사용법을 허용할 수 있다.
- 시스템 성능은 예상된 부하와 데이터 양에서 필수적인 사용 사례를 충분히 만족한다.
- 시스템은 허가되지 않은 접근과 오남용을 방지한다.
결함
- 잘못될 수 있는 일을 일컫는 말로, 장애(Failure)와 동일하지 않음
- 결함은 사양에서 벗어난 시스템의 한 구성요소로 정의
- 장애는 사용자에게 필요한 서비스를 제공하지 못하고 시스템 전체가 멈춤을 의미
- 결함을 예측하고 대처할 수 있는 시스템을 내결함성(fault-tolerant) 또는 탄력성(resilient)을 지녔다고 함.
- 모든 종류의 결함을 견딜 수 있는 시스템을 만드는 건 실현 불가능
- 따라서 특정 유형의 결함 내성에 대해서만 이야기 하는 것이 타당함.
- 넷플릭스의 카오스 몽키, 일부러 장애를 일으켜 시스템이 잘 버티는지 검증하는 방법.
- 하지만 보안 같은 문제는 훈련보다는 예방이 더 중요
🌀 하드웨어 결함
- (가장 일반적) 각 하드웨어 구성 요소에 중복(redundancy)을 추가하는 방법
- 구성 요소 하나가 죽으면, 중복된 구성요소를 대신 활용할 수 있음. (100프로 해결책은 아님)
- 디스크는 RAID 구성으로 설치
- 서버는 이중 전원 디바잉스와 핫 스왑 가능한 cpu
- 데이터 센터는 건전지와 예비 전원용 디젤 발전기를
- 구성 요소 하나가 죽으면, 중복된 구성요소를 대신 활용할 수 있음. (100프로 해결책은 아님)
- 데이터 양과 애플리케이션의 계산 요구가 늘어나면서
- 이와 비례해 하드웨어 결함율도 증가함.
- AWS와 같은 클라우드 플랫폼은 가상 장비 인스턴스가 별도의 경고 없이 사용할 수 없게 되는 상황이 일반적
- 애초에, 단일 장비 신뢰성 보다 유연성과 탄력성을 우선적으로 처리할게 끔 설계됨.
- 소프트웨서 내결함성 기술을 사용하거나, 하드웨어 중복성을 추가하는 방향으로 점점 옮겨가고 있음.
- 이런 시스템에는 운영상 장점이 있음.
- 예를 들어 장비를 재부팅해야 하는경우, 별도의 시스템 중단 없이 작업을 수행할 수 있음.
🌀 소프트웨어 오류
하드웨어 결함 ≠ 소프트웨어 결함
- 하드웨어는 서로 독립적
- 따라서, 한 장비의 디스크가 고장 나도 다른 장비에 직접 영향은 없음.
- 소프트웨어 내 체계적 오류 (systematic error)
- 소프트웨어 결함은 하드웨어처럼 독립적이지 않고, 오히려 전체 시스템에 영향을 확 퍼지게 함.
- 예측이 어렵고, 예상치 못한 상황에서 터지기 때문에 하드웨어보다 더 위험하다.
- 특정 상황에 의해 발생하기 전까지 오랫동안 나타나지 않음.
- 신속한 해결책이 없음
- 다만, 격리(process isolation), 테스트, 모니터링, 경고 시스템 등을 통해 피해를 줄일 수는 있음
🌀 인적 오류
사람이 미덥지 않음에도 시스템을 어떻게 신뢰성있게 만들까?
- 좋은 인터페이스 설계
- 잘 설계된 추상화, API, 관리 인터페이스를 쓰면 "옳은 일"은 쉽게 하고, "잘못된 일"은 막을 수 있음.
- 예: DB 트랜잭션을 제공하면, 개발자가 실수로 데이터 무결성을 깨트리는 일이 줄어듦.
- 샌드박스 제공
- 사람이 자주 실수하는 부분을 분리해서, 실제 사용자에게 영향 없는 환경에서 안전하게 실험 가능하도록
- 예: 은행 시스템에서 "모의 계좌"를 제공해서 개발자나 QA가 실제 돈을 건드리지 않고 테스트 가능.
- 모든 단계에서 철저한 테스트
- 단위 테스트(Unit Test)부터 전체 시스템 통합 테스트, 자동화된 수동 테스트까지 철저히.
- 특히 코너 케이스(corner case, 극단적인 상황)를 테스트하는 게 중요.
- 예: 계좌 이체 시 잔고가 0원일 때 등.
- 빠른 롤백 / 롤아웃 전략
- 장애가 생겨도 신속하게 이전 상태로 돌릴 수 있어야 함.
- 설정 변경 내역을 빠르게 되돌리거나(rollback), 새 코드를 점진적으로 배포(rollout)하는 방식.
- 예: 서버에 장애 발생 시, 문제가 된 버전만 되돌려서 전체 사용자에게 피해 최소화.
- 모니터링과 원격 측정(telemetry)
- 성능 지표(metrics)와 오류를 상세하고 명확히 기록·관찰해야 함.
- 문제 발생을 조기에 감지하고, 경고를 보내고, 원인 파악에 도움 줌.
- 예: 메시지 큐에 들어오는 메시지 수와 처리되는 메시지 수를 비교 → 차이가 나면 경고.
- 조직 교육과 실습
- 시스템 안정성은 기술만이 아니라 사람의 훈련도 중요.
- 평소에 실습을 통해 위기 대응 훈련을 해 두면 실제 장애 시 침착하게 대응할 수 있음.
- 예: 카오스 몽키(Chaos Monkey) 같은 훈련 도구.
🌀 신뢰성은 얼마나 중요할까?
- 신뢰성은 모든 소프트웨어에서 중요함.
- 다만 서비스 성격에 따라 비용과 신뢰성 사이에서 균형을 잘 잡아야 함.
- 예를 들어, MVP 모델을 빨리 만들어야 하는 경우 (비용 > 신뢰)
❐ 확장성
- 시스템이 안정적으로 동작한다고 해서 미래에도 안정적일거라는 보장은 없음.
- 성능 저하를 유발하는 흔한 이유 중 하나는 부하 증가
- 확장성은 증가한 부하에 대처하는 시스템 능력을 설명하는데 사용하는 용어
- 하지만, 시스템에 부여하는 일차원적인 표식은 아님
- 확장을 논한다는 건... 아래와 같은 질문을 고려한다는 의미!
- "시스템이 특정 방식으로 커지면 어떻게 대처해야 할까?"
- "추가 부하를 다루기 위해 계산 자원을 어떻게 투입할까?"
🌀 부하 기술하기
- 무엇보다 시스템의 현재 부하를 간결하게 기술해야 함.
- 그래야 부하 성장 질문을 논의할 수 있음.
- 부하를 표현하는 방식 ➔ 부하 매개변수(load parameter)
- 웹 서버의 초당 요청 수
- 데이터베이스의 읽기 대 쓰기 비율
- 대화방의 동시 활성 사용자 (active user)
- 캐시 적중률 등...
Tweet을 예로 이해하기
- 트위터의 확장성 문제는 주로 트윗 양이 아닌 "팬-아웃"(fan-out) 때문
- 개별 사용자는 많은 사람을 팔로우하고 많은 사람이 개별 사용자를 팔로우한다.
- 이 두 가지 동작을 구현하는 방법은 크게 2가지
- 방식1
- 트윗 작성은 간단히 새로운 트윗을 트윗 전역 컬렉션에 삽입
- 사용자가 자신의 홈 타임라인을 요청하면
- 팔로우하는 모든 사람을 찾고
- 이 사람들의 모든 트윗을 찾아 시간순으로 정렬해서 합침

- ➔ 이 방식은 시스템이 홈 타임라인 질의 부하를 버텨내기 위해 고군분투, 그 결과 방식2로 전환
- 방식2
- 각 수신 사용자용 트윗 우편함처럼 개별 사용자의 홈 타임라인 캐시를 유지한다.
- 사용자가 트윗을 작성하면 해당 사용자를 팔로우하는 사람을 모두 찾고, 캐시에 새로운 트윗을 삽입

- 이 방식의 단점(불리한 점)
- 트윗 작성이 많은 부가 작업을 필요로 하다는 것
- 그래서 현재는? Hybrid 형태로 최종 전개됨.
- 팔로워 수가 매우 많은 소수 사용자는 팬-아웃에서 제외!
- 방식1
- 트위터 사례에서의 부하 매개변수(load parameter)
- 사용자당 팔로워의 분포 ➔ 이는 팬-아웃 부하를 결정하기 때문에
🌀 성능 기술하기
성능 수치가 필요한 두 가지 질문
- 부하 매개변수를 증가시키고 시스템 자원은 변경하지 않고 유지하면 시스템 성능은 어떻게 영향을 받을까?
- 부하 매개변수를 증가시켰을 때 성능이 변하지 않고 유지되길 원한다면 자원을 얼마나 늘려야 할까?
성능 지표 : 처리량 vs 응답 시간
- 처리량 (Throughput)
- 하둡과 같은 일괄 처리 시스템에서 중요
- 응답 시간 (Response time)
- 온라인 시스템에서 더 중요
응답 시간은 분포(Distribution)로 봐야함!
- 동일한 요청을 여러 번 보내도, 매번 응답 시간은 다름.
- 어떤 요청은 매우 빠르지만, 어떤 요청은 매우 느림(특이값, outlier)
- Ex) DB 페이지 폴트, 네트워크 지연, GC(가비지 컬렉션) 등으로 특정 요청만 오래 걸릴 수 있음.
"전형적인" 응답 시간을 알고 싶다면 평균은 그다지 좋은 지표가 아니다!
- (산술) 평균
- 단순히 모든 응답 시간을 더해서 나눈 값.
- 하지만 느린 요청 몇 개(outlier)가 평균을 왜곡할 수 있음.
- 따라서 얼마나 많은 사용자가 실제로 지연을 경험했는지 알려주지 않음.
- 중앙값
- 응답 시간을 빠른 순서대로 정렬했을 때 중간값.
- 사용자 요청의 절반은 중앙값 응답 시간 미만, 나머지 반은 중앙값 보다 오래 걸림
- (상위) 백분위
- 값이 얼마나 좋지 않은지 알아볼 때 좋음
- 95분위, 99분위, 99.9분위가 일반적임
- 꼬리 지연 시간 (Tail latency)
- 서비스의 사용자 경험에 직접 영향을 주기 때문에 중요함.
- 아마존은 응답 시간이
- 100밀리초 느려지면 판매량 1% 감소
- 1초 느려지면 고객 만족도 지표 16% 감소
더보기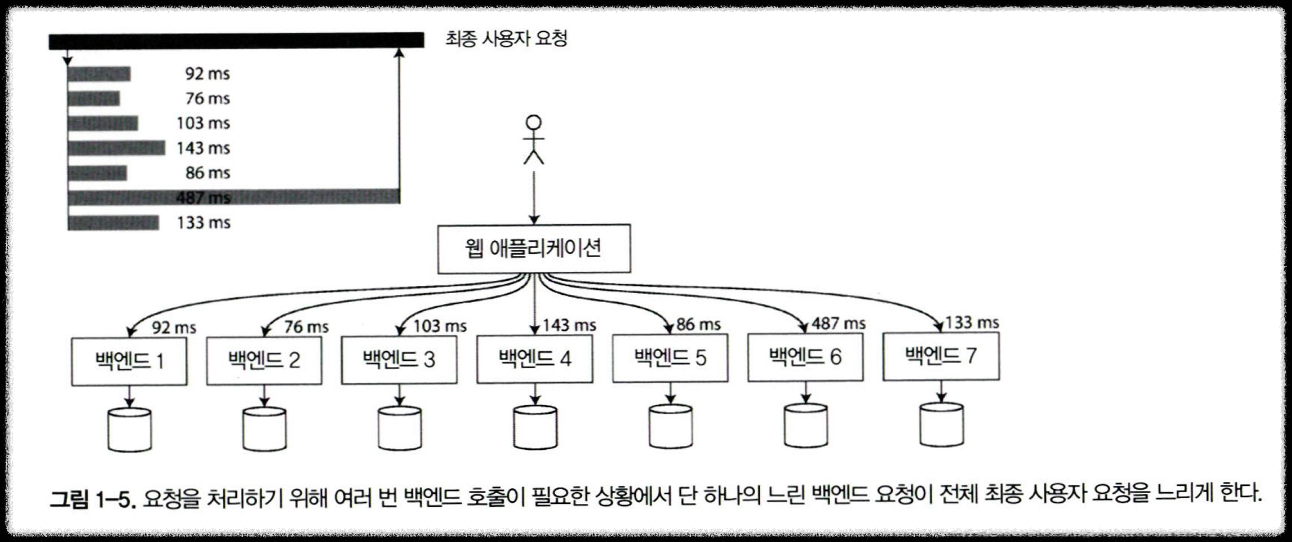
- 꼬리 지연 증폭
- 여러 개의 요청을 병렬로 보내도, 그중 가장 느린 요청 하나가 전체 응답 속도를 늦추는 현상.
- 측정 방법
- 지속적으로 백분위를 계산해야 함.
- 예를 들어, 지난 10분간 요청의 응답 시간을 롤링 윈도(Rolling window)로 유지하고 싶다면
- 1분마다 구간 내 중앙값과 다양한 백분위를 계산해 각 지표를 그래프에 그리면 됨.
- 지속적으로 백분위를 계산해야 함.
- 구현 기법
- Forward Decay, t-digest, HdrHistogram 같은 알고리즘
- 메모리와 CPU 비용 최소화하면서 정확한 백분위 근사치 계산 가능.
- 값이 얼마나 좋지 않은지 알아볼 때 좋음
큐 대기 지연(Queue delay)
- 큐 대기 지연은 높은 백분위에서 응답 시간의 상단 부분을 차지함
- 서버는 동시에 처리할 수 있는 요청 수(예: CPU 코어 수)에 한계가 있음.
- 그래서 요청이 몰리면 처리할 때까지 줄을 서야 함 → 대기 지연 발생.
- 특히 소수의 느린 요청 때문에 전체 응답 시간이 길어지는 경우가 많음.
- 선두 차단 (Head-of-line blocking)
- 요청을 차례대로 처리하는 과정에서 앞에 있는 느린 요청이 뒷 요청까지 막아버리는 현상.
- Ex) B 대기 시간 = A 요청(5초) + B 요청(0.5초) = 5.5초
- 결국 전체 응답 시간이 불필요하게 길어짐.
- 요청을 차례대로 처리하는 과정에서 앞에 있는 느린 요청이 뒷 요청까지 막아버리는 현상.
- 확장성을 테스트할 때는 부하를 인위적으로 만들어야 함.
- 이때, 부하 생성 클라이언트는 응답 시간과 독립적으로 요청을 지속적으로 보내야 함.
- 클라이언트가 다음 요청을 보내기 전에 이전 요청이 완료되길 기다린다면?
- 큐에서는 대기 지연 발생 안 함.
- 인위적인 부하가 안 만들어짐. 즉, 잘못된 테스트를 하게되는 꼴
🌀 부하 대응 접근 방식
부하 매개변수가 어느 정도 증가하더라도 좋은 성능을 유지하려면?
- 처음에 잘 설계한 시스템이라고 해서, 서비스가 10배 성장했을 때도 그대로 쓸 수 있는 건 아님.
- 급성장하는 서비스를 맡고 있다면, 부하 규모의 자릿수가 바뀔 때마다 혹은 그보다 자주 아키텍처 재검토 필요
확장의 두 가지 방식
- 용량 확장 (Scaling Up, 수직 확장, Vertical Scaling)
- 더 강력한 장비로 교체 → 서버 1대를 성능 좋은 장비로 업그레이드.
- 예: CPU 더 빠른 걸로 교체, 메모리 늘리기.
- 장점: 구조 단순.
- 단점: 장비 가격이 기하급수적으로 비싸짐 + 한계가 있음.
- 규모 확장 (Scaling Out, 수평 확장, Horizontal Scaling)
- 여러 대의 장비로 작업을 분산 처리.
- 보통 비공유(shared-nothing) 아키텍처라고 부름 → 각 서버가 독립적으로 일함.
- 장점: 상대적으로 저렴, 확장성 높음.
- 단점: 시스템 구조가 복잡해짐(분산 처리, 동기화, 데이터 일관성 문제 해결 필요).
➔ 이 두 가지를 별개로 생각하지 말고, 실용적인 접근 방식의 조합이 필요함!
탄력적 (elastic)
- 부하 증가를 감지하면 컴퓨팅 자원을 자동으로 추가할 수 있음.
- 물론 그렇지 않은 시스템도 있음. 이런 경우 수동으로 확장해줘야 함.
- 탄력적인 시스템은 부하를 예측할 수 없을 만큼 높은 경우 유용함.
- 수동으로 확장하는 시스템이 더 간단하고 운영상 예상치 못한 일이 더 적음
상태 비저장 (stateless)
- 다수의 장비에 stateless 서비스를 배포하는 건 간단.
- 하지만, 단일 노드에 stateful 데이터 시스템을 분산 설치하는 일은 많은 복잡도가 추가적으로 발생
범용적이고 모든 상황에 맞는(one-size-fits-all) 확장 아키텍처는 없다!
- 모든 상황에 똑같이 잘 맞는 마법 같은 확장 방법은 없음.
- 아키텍처를 결정하는 요소는 많음.
- 읽기/쓰기 양
- 저장 데이터 크기
- 복잡도
- 응답 시간 요구사항
- 접근 패턴 등등...
특정 애플리케이션에 적합한 확정성을 갖춘 아키텍쳐를 설계하기 위해선...
- 주요 동작이 무엇이고, 잘 하지 않는 동작이 무엇인지에 대한 가정을 세워햐 함.
- 이 가정이 곧 "부하 매개변수"
- 이 가정이 잘못되면 확정에 대한 엔지니어링 노력은 헛수고가 되며, 최악의 경우 역효과를 낳음.
- 스타텁 초기 단계나 검증되지 않은 제품의 경우에 부하에 대비해 확장하기 보단
- 빠르게 반복해서 제품 기능을 개선하는 작업이 좀 더 중요함.
❐ 유지보수성
주의를 기울여야 할 소프트웨어 시스템 설계 원칙
- 운용성(operability)
- 운영팀이 시스템을 원할하게 운영할 수 있도록 만들어라.
- 단순성(simplicity)
- 시스템에서 복잡도를 최대한 제거해 새로운 엔지니어가 이해하기 쉽게 만들어라.
- 발전성(evolvability)
- 엔지니어가 이후에 시스템을 쉽게 변경할 수 있게 하라.
- 그래야 요구사항 변경 같은 예기치 않은 사용 사례를 적용하기 쉽다.
- 이 속성은 우연성, 수정 가능성, 적응성으로 알려져 있다.
➔ 신뢰성, 확장성을 달성하기 쉬운 해결책은 없음.
➔ 그보다 운용성, 단순성, 발전성을 염두에 두고 시스템을 생각하려 노력해야 함.
🌀 운용성 : 운영의 편리함 만들기
➔ 시스템이 지속해서 원할하게 작동라혀면 운영팀은 필수
좋은 운영팀이 일반적으로 하는 것들.

좋은 운영성이란?
- 동일하게 반복되는 태스크를 쉽게 수행할게 끔 만들어 운영팀이 고부가가치 활동에 노력을 집중하는 것.
데이터 시스템은 동일 반복 태스크를 쉽게 하기 위해 아래 항목등을 포함해 다양한 일을 수행

🌀 단순성: 복잡도 관리
- 시스템이 커짐에 따라 시스템은 매우 복잡하고 이해하기 어려워짐.
- 복잡도 수러에 빠지 소프트웨어 프로젝트를 때론 커다란 진흙 덩어리 (big ball of mud)로 묘사함
복잡도 증가로 인해 파생되는 문제들
- 같은 시스템에서 작업해야 하는 모든 사람의 진행을 느리게 만들어, 유지보수 비용 증가
- 예산과 일정 초과
- 변경이 있을 때, 버그가 생길 위험이 더 큼
- 개발자가 시스템을 이해하고 추론하기 어려워짐
우발적 복잡도(accidental complexity) 줄이기
- 최상의 방법은 좋은 추상화
- 깔끔하고 직관적인 외관 아래로 많은 세부 구현을 숨길 수 있음.
- 다른 다양한 애플리케이션에서도 사용 가능
- 이러한 재사용은 고품질 소프트웨어로 이어짐
➔ 이렇게 좋은 추상화를 하게 되면, 큰 시스템의 이부를, 잘 정의되고 재사용 가능한 구성 요소로 추출할 수 있게 함.
🌀 발전성: 변화를 쉽게 만들기
책에서 말하려는 애자일은...
- 애자일 작업 패턴은 변화에 적응하기 위한 프레임워크를 제공함.
- 일반적인 애자일(Agile) 설명은 작은 규모(소스코드 몇 개, 단일 애플리케이션 수준)에 집중돼 있음.
- 하지만 이 책은 대규모 데이터 시스템 수준에서 어떻게 민첩성을 확보할 수 있을지에 초점을 맞춤.
- 예: 트위터가 홈 타임라인 시스템을 리팩토링하면서 접근 방식 1 → 접근 방식 2로 변경.
- 즉, 시스템 수준에서도 "애자일하게 변화할 수 있는 방법"을 고민해야 함.
민첩성
- 데이터 시스템 변경을 쉽게 하고, 새로운 요구사항에 맞게 시스템을 빠르게 수정할 수 있는 능력을 말함.
- 여기에는 시스템의 간단함(simplicity), 추상화(추상화 수준의 적절함)와 밀접하게 관련됨.
- 단순한 시스템은 이해하기 쉽고, 그래서 변경하기도 쉬움.
- 반대로 복잡한 시스템은 수정하기가 매우 어려움.
발전성
- 저자는 "민첩성(agility)"이라는 단어 대신 발전성(evolvability)이라는 표현을 쓰겠다고 함.
- 단순히 빠르게 바꾸는 것(agility)뿐 아니라, 장기적으로 시스템이 지속적으로 진화할 수 있어야 함을 담기 위해.
❐ 정리
애플리케이션이 유용하려면 다양한 요구사항을 충족시켜야 함.
- 기능적 요구 사항
- 비기능적 요구 사항
신뢰성
- 결함이 발생해도 시스템이 올바르게 동작하게 만든다는 의미
- 결함은 하드웨어와 스프트웨어 버그와 인가에게 있을 수 있음
- 내결함성 기술은 최종 사용자에게 특정 유형의 결함을 숨길 수 있게 해줌
확장성
- 부하가 증가해도 좋은 성능을 유지하기 위한 전략을 의미
유지보수성
- 본질은 시스템에서 작업하는 엔지니어와 운영팀의 삶을 개선하는데 있음.
- 좋은 추상화는
- 복잡도를 줄이고
- 쉽게 시스템을 변경할 수 있게하며,
- 새로운 사용 사례에 적용하는데 도움이 됨.
- 좋은 운용성이란
- 시스템의 건강 상태를 잘 관찰할 수 있고
- 시스템을 효율적으로 관리하는 방법을 보유한다는 의미
안타깝지만...
- 애플리케이션을 신뢰할 수 있고, 확장 가능하며 유지보수하기 쉽게 만드는 심플한 해결책은 없음.
- 하지만 여러 애플리케이션에서 계속 재현되는 특정 패턴과 기술이 있음.
- 잎으로 배울거임.
'Book > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| 5장. 복제 (0) | 2025.09.14 |
|---|---|
| Part2. 분산 데이터 (0) | 2025.09.13 |
| 4장. 부호화와 발전 (Encoding & Evolution) (0) | 2025.09.06 |
| 3장. 저장소와 검색 (0) | 2025.08.30 |
| 2장. 데이터 모델과 질의 언어 (0) | 2025.08.23 |