❐ Description
- 데이터 모델의 중요성
- 데이터 모델은 단순히 "데이터를 어떻게 저장할까?"의 문제가 아님.
- 소프트웨어가 문제를 어떻게 생각하고 해결할 것인지에까지 영향을 줌
- 여러 층위(Levels)에서의 데이터 모델
- 데이터를 서로 다른 관점과 레벨에서 각자 다른 방식으로 모델링 함.
- 각 계층은 명확한 데이터 모델을 제공해 하위 계층의 복잡성을 숨긴다.
- 각 계층이 중요하게 생각할 부분은, 하위 계층의 관점에서 데이터를 표현하는 방법
- 이번 장에서는
- 데이터 저장과 질의를 위한 다양한 범용 데이터 모델을 살펴본다.
- 특히 관계형, 문서형, 그래프 기반 데이터 모델을 비교한다.
❐ 관계형 모델과 문서 모델
🌀 관계형 모델
- 오늘 날 흔히 씀
- 데이터는
- SQL에서 테이블이라고 불리는 관계(Relation)로 구성되고,
- 각 관계는 SQL에서 Row라고 불리는 순서 없는 튜플(Tuple) 모음.
- 관계형 모델의 목표는 정리된 인터페이스 뒤로 구현 세부 사항을 숨기는 것.
🌀 NoSQL의 탄생
- Not Only SQL로 재해셕
- NoSQL 채택의 주요 원동력
- 대규모 데이터셋이나 매우 높은 쓰기 처리량 달성을 관계형 데이터베이스보다 쉽게 할 수 있는 뛰어난 확장성의 필요
- 상용 데이터베이스 제품보다 무료 오픈소스 소프트웨어에 대한 선호도 확산
- 관계형 모델에서 지원하지 않는 특수 질의 동작
- 관계형 스키마의 제한에 대한 불만과 더욱 동적이고 표현력이 풍부한 데이터 모델에 대한 바람[5]
- 가까운 미래에는 관계형과 비관계형이 함께 사용될 거임.
🌀 객체 관계형 불일치
- 임피던스 불일치 (Impedence mismatch)
- 오늘날 애플리케이션은 주로 객체지향 언어로 개발
- 하지만 SQL 데이터 모델은 객체지향과 맞지 않는다는 비판이 존재
- 데이터를 관계형 DB에 저장하려면
- 애플리케이션 객체(클래스, 오브젝트) 와 DB 모델(테이블, 행, 열) 사이를 이어주는 전환 계층이 필요
- 이 불편한 간극을 임피던스 불일치(impedance mismatch) 라고 부름
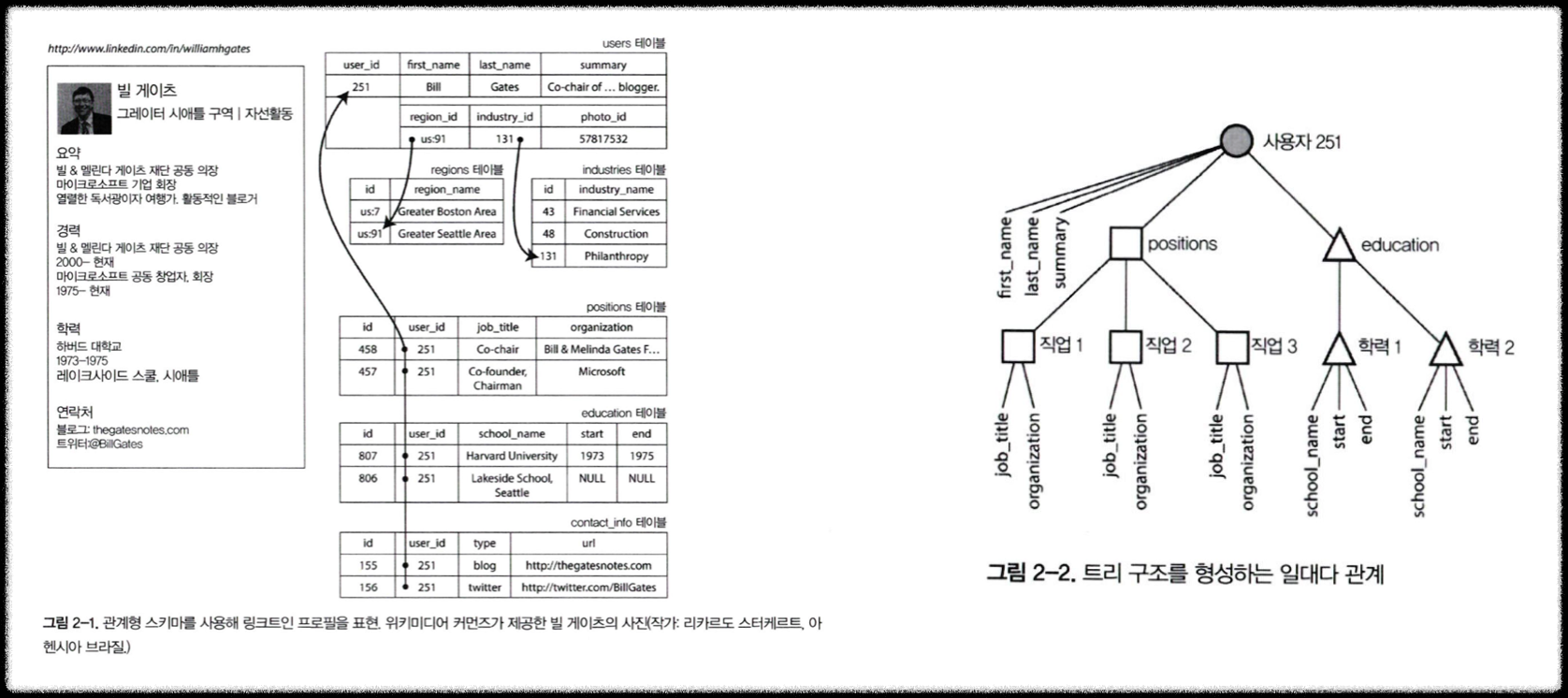
🌀 다대일과 다대다 관계
- 왜 ID를 사용하는가
- 데이터를 단순히 문자열로 저장한다면 아래와 같은 문제가 생김
- 중복: "그레이터 시애틀 구역", "Greater Seattle Area" 같은 표현이 섞임
- 갱신 어려움: 도시 이름이 바뀌면 모든 레코드를 수정해야 함
- 검색 불편: "워싱턴에 있는 자선활동"을 찾기 힘듦
- 다국어 지원 불가: 다른 언어로 변환 어려움
- 따라서 ID를 두고, 실제 이름은 별도의 참조 테이블에서 관리한다.
- 이렇게 하면 중복 제거, 갱신 용이, 검색 효율성, 다국어 지원이 가능하다.
- 데이터를 단순히 문자열로 저장한다면 아래와 같은 문제가 생김
- 다대일 관계 (Many-to-One)
- 중복된 데이터를 정규화 하기 위해서 필요한 구조
- 정의: 여러 개의 데이터가 하나의 기준값에 연결되는 구조
- 관계형 DB: 외래키(Foreign Key) + JOIN 으로 쉽게 구현
- 문서형 DB
- JOIN 지원이 약해서 적합하지 않음
- 트리 구조로 표현
- 다대다 관계 (Many-to-Many)
- 정의: 데이터가 서로 여러 개씩 연결될 수 있는 구조
- 관계형 DB: 보통 Join Table 사용
- 그래프 DB: 노드와 엣지로 직관적으로 표현 가능
🌀 문서 데이터베이스는 역사를 반복하고 있나?
- IMS의 설계는 계층 모델이라고 부르는 상당히 간단한 모델을 사용했음.
- 계층 모델은 문서 데이터베이스에서 사용하는 JSON 모델과 비슷함.
- 일대다는 잘동작함
- 다대다 관계 표현은 어려웠고, 조인을 지원하지 않음.
🌀 네트워크 모델
- 코다실 모델이라고도 부름
- 계층 모델을 일반화
- 계층 모델의 트리 구조에서 모든 레코드는 정확하게 하나의 부모가 있음.
- 네트워크 모델에서 레코드는 다중 부모가 있을 수 있음.
- 레코드간 연결은 프로그래밍 언어의 포인터와 비슷함
🌀 관계형 모델
- 옵티마이져가 최적화를 진행함.
🌀 문서 데이터베이스와 비교
- 다대일, 다대다 표현할 때는 근본적으로 다르지 않음.
- 문서 : 문서 참조
- 관계 : 외래 키
🌀 관계형 데이터베이스와 오늘날의 문서 데이터베이스
- 비교시 고려할 점
- 관계형 DB와 문서 DB를 비교할 때는 단순히 데이터 모델 차이만이 아니라,
- 내결함성(fault tolerance) (5장에서 다룸)
- 동시성 처리(concurrency control) (7장에서 다룸) 같은 요소도 중요
- 하지만 이 장에서는 데이터 모델의 차이에 집중
- 관계형 DB와 문서 DB를 비교할 때는 단순히 데이터 모델 차이만이 아니라,
- 문서 데이터 모델을 선호하는 이유
- 스키마 유연성:
- 문서 DB는 스키마를 엄격히 고정하지 않아 데이터 구조를 쉽게 변경 가능.
- 지역성(Locality)에 기반한 성능:
- 관련 데이터가 한 문서 안에 모여 있기 때문에 읽기/쓰기 성능이 더 좋을 수 있음.
- 애플리케이션 친화적:
- 어떤 애플리케이션의 경우, 사용하는 데이터 구조가 문서 DB 모델과 더 잘 맞음.
- 스키마 유연성:
- 관계형 DB의 장점
- 조인(Join), 다대일(Many-to-One), 다대다(Many-to-Many) 관계를 더 잘 지원.
- 따라서 관계가 복잡한 데이터를 다루기에는 여전히 RDB가 강점.
🌀 어떤 데이터 모델이 애플리케이션 코드를 간단하게 할까?
- 문서 DB 장점
- 애플리케이션 코드와 구조가 유사 → 코드 단순화
- 스키마 유연성 → 빠른 변화 대응
- 스키마 변경 시 마이그레이션 불필요
- 문서 DB 단점
- 복잡한 관계(조인, 다대다)에 불리
- 데이터 구조가 불규칙할 경우 관리 어려움
- 관계형 DB 장점
- 관계 처리(조인, 다대다)에 강함
- 정해진 스키마로 일관된 데이터 보장
🌀 질의를 위한 데이터 지역성
- 문서 저장의 장점
- 문서는 보통 JSON이나 BSON 같은 형식으로 저장됨.
- 하나의 문서에 관련 데이터를 모두 담아두기 때문에
- 애플리케이션이 문서를 불러올 때 저장소 지역성(storage locality) 이 좋아짐.
- 만약 쪼개서 저장한다면?
- 데이터를 여러 테이블로 나누면 조인을 해야 하고, 여러 번 디스크 탐색이 필요해 성능 저하.
- 반면 문서는 한 번에 필요한 정보를 가져올 수 있어 효율적.
- 제한점
- 문서 크기가 너무 커질 수 있음.
- 일반적으로 문서를 작게 유지하고, 필요 없는 중복은 피하는 것이 권장됨.
🌀 문서 DB와 관계형 DB의 통합
- 관계형 DB도 XML/JSON 지원
- 문서 DB의 조인 지원
- 일부 문서 DB(예: 리싱3DB, MongoDB 드라이버)는 조인 비슷한 기능을 제공.
- 하지만 보통 클라이언트 측에서 수행 → 네트워크 오버헤드 때문에 느릴 수 있음.
- 경향
- 시간이 지날수록 관계형 DB와 문서 DB는 점점 더 닮아감.
- 서로 부족한 부분을 보완하고 있음.
- 따라서 애플리케이션은 데이터 성격에 따라 혼합 사용하는 게 현실적인 선택.
❐ 데이터를 위한 질의 언어
🌀 선언형 질의 언어 (SQL)
- SQL을 정의할 때 관계대수의 구조를 유사하게 따랐음
- σ(시그마) : 관계 대수에서 조건을 만족하는 튜플(행)을 선택하는 연산자.
- 데이터베이스 엔진의 상세 구현이 숨겨져 있어, 질의를 변경하지 않고도 DB 성능을 향상 시킬 수 있음.
- 결과가 충족해야 하는 조건과 데이터를 어떻게 변환해야 할지를 지정하면 됨.
🌀 명령형 질의 언어 (IMS, CODASYL)
- 특정 순서로 특정 연산을 수행할게 끔 컴퓨터에게 전달
🌀 웹에서의 선언형 질의
- 선언형 스타일링(CSS, XPath) 은 규칙만 정의 → 브라우저가 알아서 최적화.
- 명령형 스타일링(JavaScript) 은 동작을 직접 지정해야 함 → 코드 길고 유지보수 어려움.
- 같은 맥락으로, SQL 같은 선언형 쿼리 언어가 명령형 API보다 훨씬 효율적이고 유지보수성이 좋음.
🌀 map reduce의 질의
- map reduce란?
- Map(매핑): 데이터를 키-값 형태로 변환 → 중간 결과 생성.
- Reduce(축소): 동일한 키를 가진 값을 합쳐 최종 결과 도출.
- 구글이 대용량 데이터 처리를 위해 만든 프로그래밍 모델.
- 선언형과 명령형 그 사이 어딘가 위치한 애매한 녀석
- 분산 처리에 적합
- MongoDB, CouchDB 같은 일부 NoSQL DB에서 지원.
- 단점
- 코드가 길고 복잡.
- 순수 함수(pure function)여야 함.
- 결국 MongoDB 같은 NoSQL도 Aggregation Pipeline을 도입
- 선언형 쿼리가 유지보수성과 최적화 측면에서 훨씬 유리하기 때문
❐ 그래프형 데이터 모델
- 그래프는 두 유형의 객체로 이루어짐
- 정점(vertex)
- 간선(edge)
- 그래프(Graph)는 다양한 알고리즘에 활용될 수 있음.
- 네비게이션 시스템: 도로 네트워크에서 두 지점 간 최단 경로 찾기.
- PageRank: 웹 그래프에서 페이지의 인기도를 계산해 검색 순위 매기기.
- 위 예시에서는 그래프의 모든 노드(정점, vertex)가 같은 종류의 데이터:
- 도로망 → 도로 교차점(junction)
- 웹 그래프 → 웹 페이지
- 소셜 그래프 → 사람
- 하지만 그래프는 꼭 동일한 타입의 노드만 저장해야 하는 건 아님.
- 이질적인 데이터(서로 다른 종류)를 하나의 그래프 안에서 일관되게 표현 가능.
- 즉, 여러 다른 객체를 한 데이터 모델 안에 담아 관계를 표현할 수 있음.
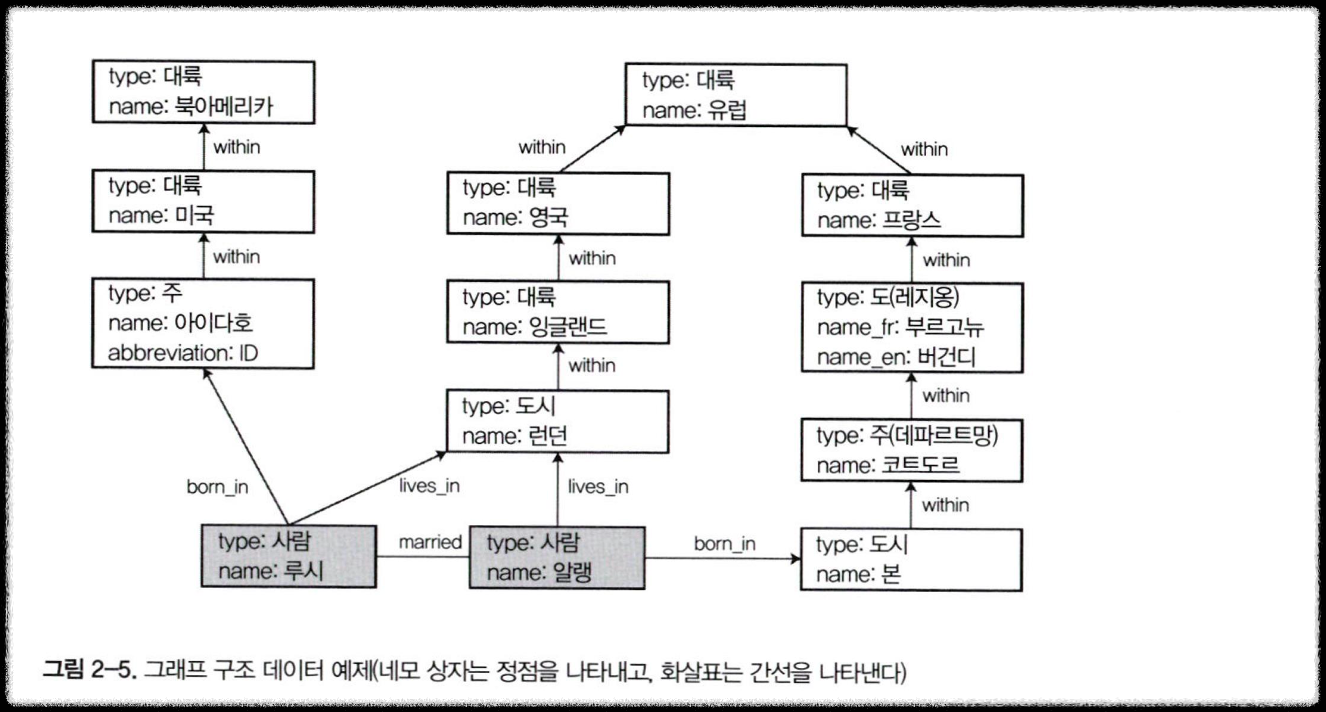
🌀 속성 그래프
- 속성 그래프 모델에서
- 각 정점은 다음과 같은 요소로 구성
- 고유한 식별자
- 유출(outgoing) 간선 집합
- 유입(incoming) 간선 집합
- 속성 컬렉션 (키-값 쌍)
- 각 간선은 다음과 같은 요소로 구성
- 고유한 식별자
- 간선이 시작하는 정점(꼬리 정점)
- 간선이 끝나는 정점(머리 정점)
- 두 정점 간 관계 유형을 설명하는 레이블
- 속성 컬렉션(키-값 쌍)
- 각 정점은 다음과 같은 요소로 구성
- 이 모델의 중요한 점
- 정점은 다른 정점과 간선으로 연결될 수 있다.
- 유입/유출 간선 탐색 용이
- 서로 다른 관계 유형도 단일 그래프 안에서 표현 가능
- 그래프 확장 용이
🌀 사이퍼 질의 언어
- 사이퍼는 속성 그래프를 위한 선언형 질의 언어
- Neo4j 그래프 데이터베이스용으로 만들어짐
🌀 SQL의 그래프 질의
- 그래프 데이터를 관계형 구조로 넣어도 SQL을 사용해 질의할 수 있을까?
- 가능은 한데 약간 어려움.
- SQL은 미리 몇 번 JOIN할지 알아야 쓸 수 있음.
- 반면에 그래프 질의는 경로 길이를 몰라도 탐색할 수 있음.
- 즉, 동일한 질의를 했을 때
- 사이퍼(Cypher): 몇 줄로 간단히 표현 가능, `WITHIN*` 같은 문법으로 경로 탐색 지원.
- SQL: 재귀 CTE를 여러 개 작성해야 하고, JOIN을 반복적으로 써야 함. 훨씬 길고 복잡.
- CTE : recursive common table expression
🌀 트리플 저장소와 스파클
- 그래프 DB의 또 다른 모델. (속성 그래프 모델과 거의 동등)
- 모든 정보를 주어(Subject), 서술어(Predicate), 목적어(Object) 의 3부분(triple)으로 저장.
- 예시 : (Lucy, type, Person) → 루시는 사람이다.
🌀 시멘틱 웹
- 트리플 저장소 데이터 모델과 완전 독립적
- 개념
- 웹 사이트는 이미 사람이 읽을 수 있는 텍스트 + 그림으로 정보를 제시하고 있음.
- 그니깐 컴퓨터가 읽게끔 기계가 판독 가능한 데이터로도 정보를 제시하는건 어떨까라는 개념
RDF (Resource Description Framework)
- 자원 기술 프레임워크
- 서로 다른 웹 사이트가 일관된 형식으로 데이터를 게시하기 위한 방법을 제안
- GPT 왈
- RDF에서 주어·서술어·목적어는 보통 URI로 표현된다.
- 그냥 WITHIN 같은 단어를 쓰는 게 아니라:
- 이런 식으로 고유한 식별자를 부여.
-
<http://my-company.com/namespace#within>
-
<http://my-company.com/namespace#lives_in>
-
- 왜 굳이 이렇게 함?
- RDF의 목표는 다른 사람의 데이터와 내 데이터를 합칠 수 있도록 하는 것.
- 만약 단순히 within이라고만 하면,
- 어떤 데이터셋은 “~안에 속하다”로,
- 다른 데이터셋은 “~내부에 존재하다”로 다르게 정의할 수 있음.
- 결국 같은 단어라도 의미가 다를 수 있음 → 충돌 발생
- 그래서 URI 전체를 사용하면 고유한 의미 공간(namespace) 을 보장할 수 있음.
- 꼭 접속 가능한 URL일 필요는 없다.
- <http://my-company.com/namespace> 라고 써도 실제로 접속할 수 없어도 괜찮음.
- 단지 "이건 내 데이터셋에서 정의한 within"이라는 네임스페이스일 뿐임.
- 그래서 예시로는 urn:example:within 같은 실제 접속 불가능한 URI도 흔히 씀.
- 파일 상단에 네임스페이스를 매핑해놓으면 계속 쓸 수 있음.
- RDF에서 주어·서술어·목적어는 보통 URI로 표현된다.
🌀 스파클 질의 언어
- RDF 데이터 모델을 사용한 트리플 저장소 질의 언어.
- 사이퍼(Cypher, 속성 그래프 DB 전용 언어)보다 먼저 만들어짐.
- 사이퍼와 문법 구조가 비슷해서, 두 언어는 굉장히 닮아 있음.
그래프 데이터베이스와 네트워크 모델의 비교
- 과거의 네트워크 데이터베이스 모델(CODASYL)과 유사함
- 하지만 그래프 DB는 네트워크 모델과 몇 가지 중요한 점에서 다름
- 스키만 제한 존재 여부
- 데이터 접근 경로
- 정렬 가능 여부
- 명령형 / 선언형
🌀 초석 : 데이터 로그 (The Foundation : Datalog)
- 스파클이나 사이퍼보다 훨씬 더 오래된 언어.
- 서술어(주어, 목적어)로 작성
- 단계를 나눠 한 번에 조끔씩 질의
- 데이터에 대해 규칙(rules) 과 논리 추론(inference) 을 적용할 수 있음.
- 즉, 단순히 데이터를 조회하는 것을 넘어서, 새로운 사실을 규칙을 통해 “추론”할 수 있는 언어.
- 장점
- SQL이나 사이퍼처럼 단순한 패턴 매칭이 아니라, 추론(logical inference) 을 지원.
- 규칙을 추가하면, 이미 존재하는 데이터에서 새로운 지식을 계속 유도 가능.
- 데이터가 복잡하면 더 효과적으로 대처할 수 있음.
🌀 정리
- 역사적으로 데이터를 하나의 큰 트리(계층)로 표현하려고 노력
- 다대다 관계를 표현하기에 트리 구조는 아쉬웠음.
- 이 문제를 해결하기 위해 관계형 모델이 고안
- 관계형 모델에도 적합하지 않은 애플리케이션이 있다~
- 요즘은 NoSQL과 같은 비관계형 데이터 저장소도 있음.
- 세 가지 모델(문서, 관계형, 그래프) 모두 현재 널리 사용되고 있음.
- 단일 만능은 없음.
'Book > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| 5장. 복제 (0) | 2025.09.14 |
|---|---|
| Part2. 분산 데이터 (0) | 2025.09.13 |
| 4장. 부호화와 발전 (Encoding & Evolution) (0) | 2025.09.06 |
| 3장. 저장소와 검색 (0) | 2025.08.30 |
| 1장. 신뢰할 수 있고 확장 가능하며 유지보수하기 쉬운 애플리케이션 (0) | 2025.08.16 |