❒ Description
Concurrency Control은 트랜잭션이 동시에 실행될 때 발생할 수 있는 여러 문제를 해결하면서, Isolation 수준을
보장하는 데 중요한 역할을 한다. 이 내용은 앞선 두 포스팅에서 학습하였다.
※ 앞선 학습 내용
DB Transaction & Concurreny Control (1)
DB Transaction & Concurreny Control (2)
오늘은 Concurrency Control 방법론을 통해 구현(보장)되며, 다수의 트랜잭션이 동시에 실행될 때 트랜잭션
간의 간섭을 제어하여 데이터의 일관성을 유지하고, 각 트랜잭션이 독립적으로 수행되는 것처럼 보이게 하는 속성인
isolation에 대해서 더 자세히 학습할 예정이다.
❒ Isolation 이상 현상들
※ 참고
1 ~ 3은 표준 SQL 기준이고, 4 ~ 9는 표준 SQL을 비판하는 논문에서 언급된 이상 현상들이다.
1. Dirty read = commit 되지 않은 데이터를 read하는 경우 (with abort)
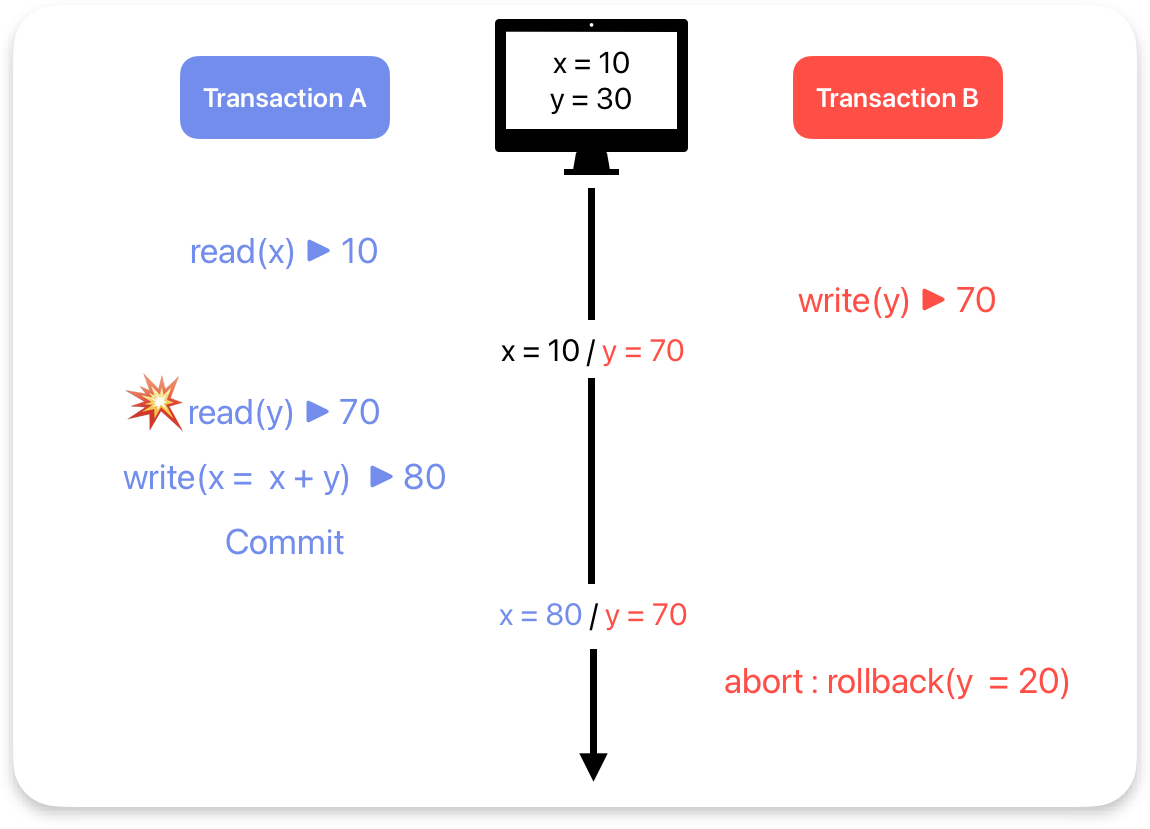
위 상황에서 Transaction B가 rollback을 하면 B가 write한 70이라는 데이터는 유요하지 않게 된다. 그리고
Transaction A는 유효하지 않은 70이라는 값을 읽고 write를 하였기 때문에 80이라는 값도 유효하지 않은 값이
된다. 이런 현상을 Drity Read라고 한다.
2. Non-repeatable read = 통일한 튜플의 데이터가 달라지는 경우
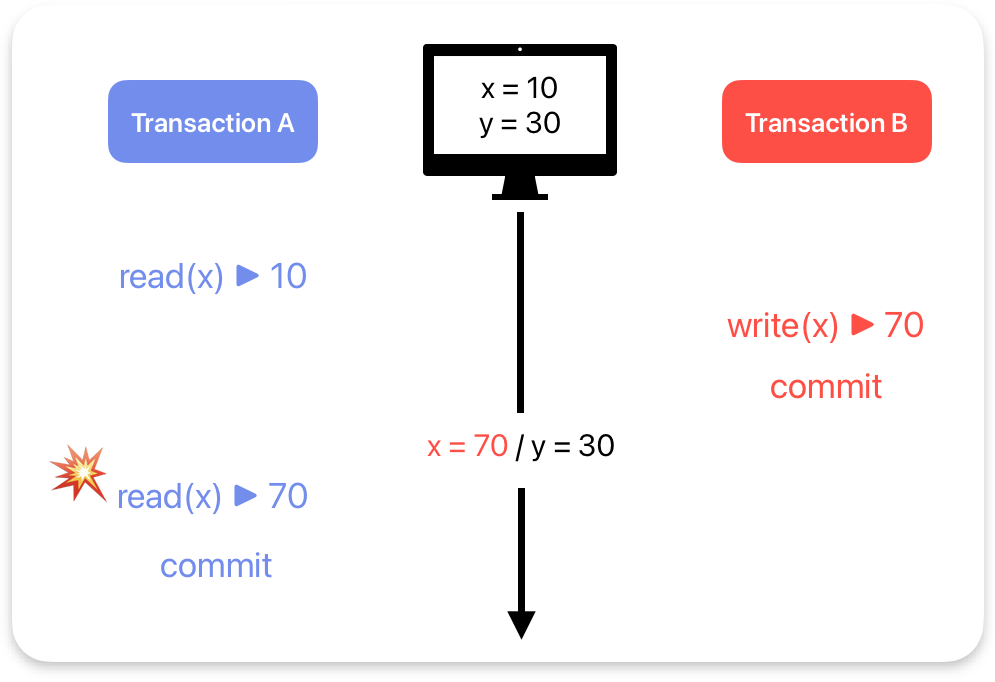
Transaction A의 입장에서 첫 번째 read에서는 10, 두 번째 read에서는 70이 반환되는 경우를 말한다.
3. Phantom read = 동일한 쿼리 ,그러나 조회 결과(들)가 다른 경우
SELECT name FROM member WHERE age = 20;위 쿼리를 수행했을 때 최초에는 2개의 값이 조회되고, 두 번째 1개의 값이 조회되는 경우를 말한다.
두 번째 조회하는 시점 이전엔 다른 트랜잭션에 의해 튜플이 생성 및 제거되기 때문에 이런 현상이 발생한다.
4. Dirty write = commit 되지 않은 데이터를 write하는 경우
5. Lost update = 다른 트랜잭션의 commit이 누락되는 경우
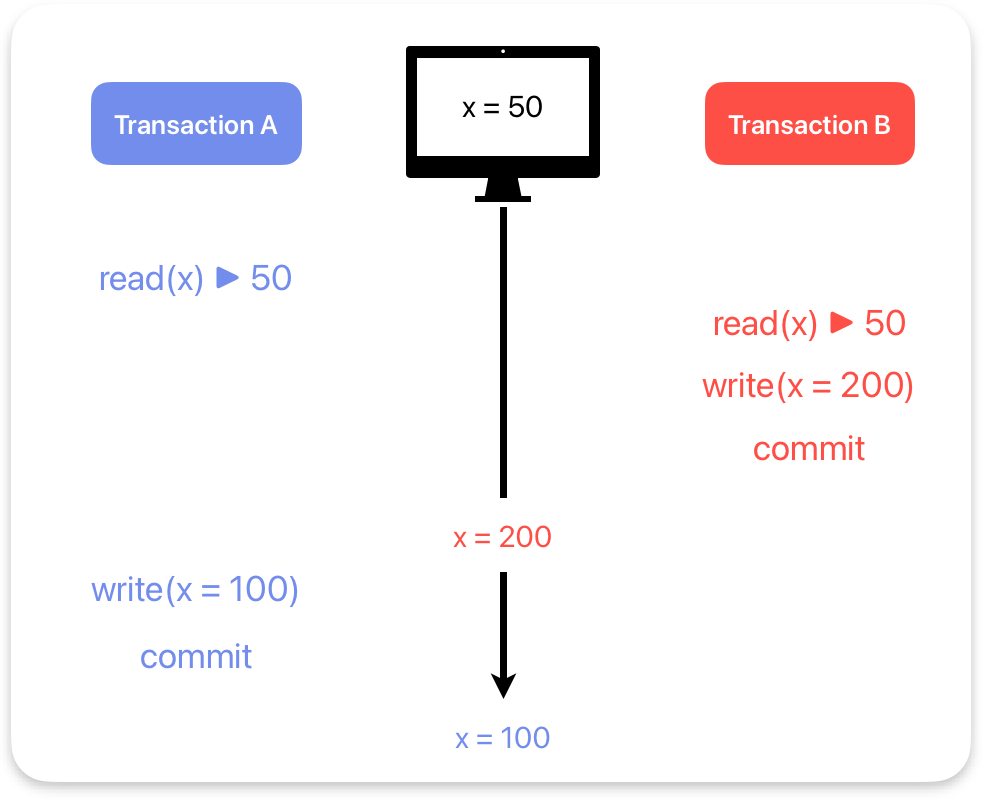
tx_B가 x를 200으로 update 했지만, 이후 tx_A가 commit 하면서 tx_B의 commit이 누락됐다.
6. Dirtry read (Edition) = commit 되지 않은 데이터를 read하는 경우 (without abort)
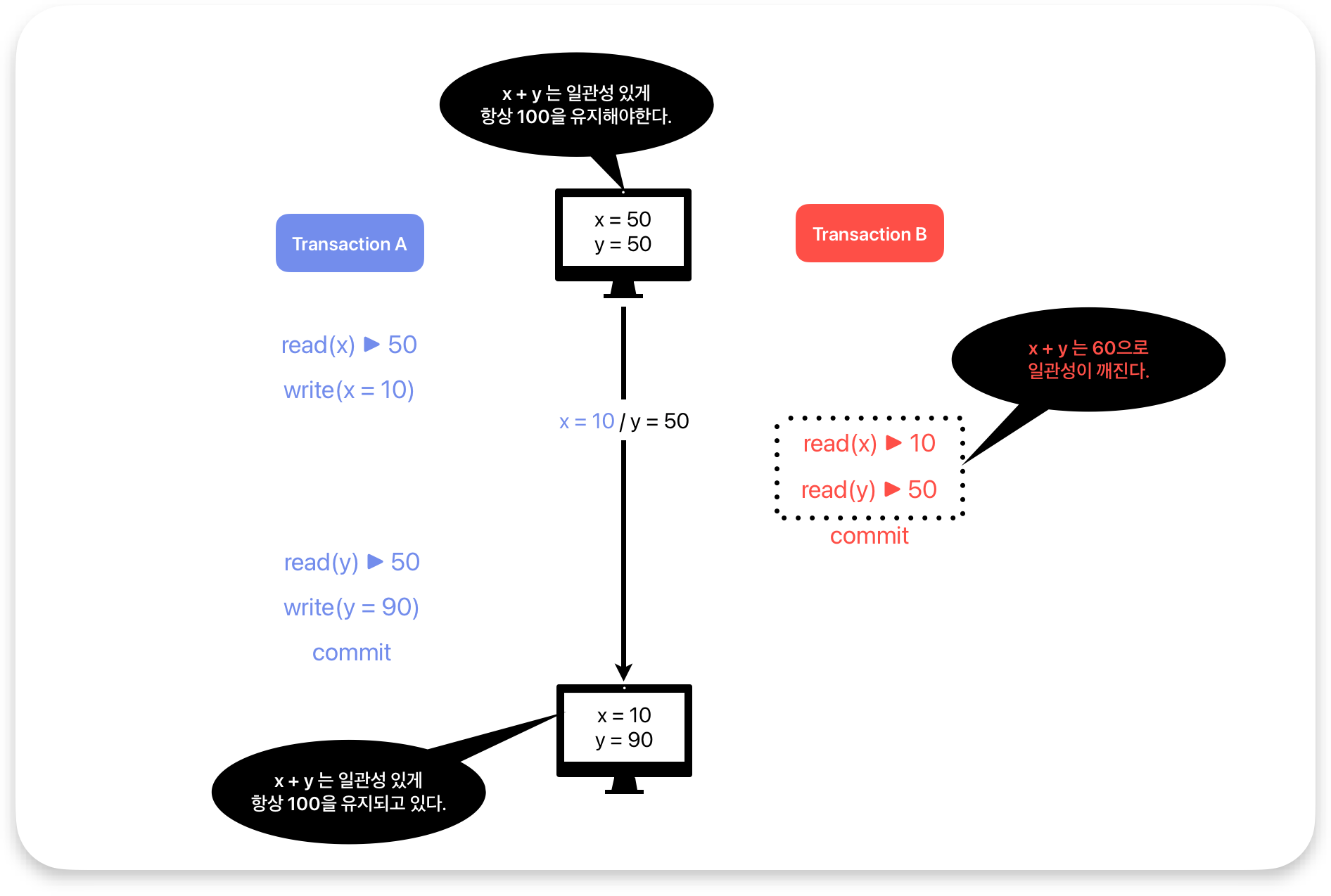
위 그림에서는 x + y 는 일관성 있게 100을 유지해야 하지만, tx_b가 read한 x,y를 더하면 60으로 일관성이
깨진다. 이렇게 abort가 발생하지 않아도 dirty read가 발생할 수 있다.
7. Read skew = 논리적 일관성 없는 데이터 read
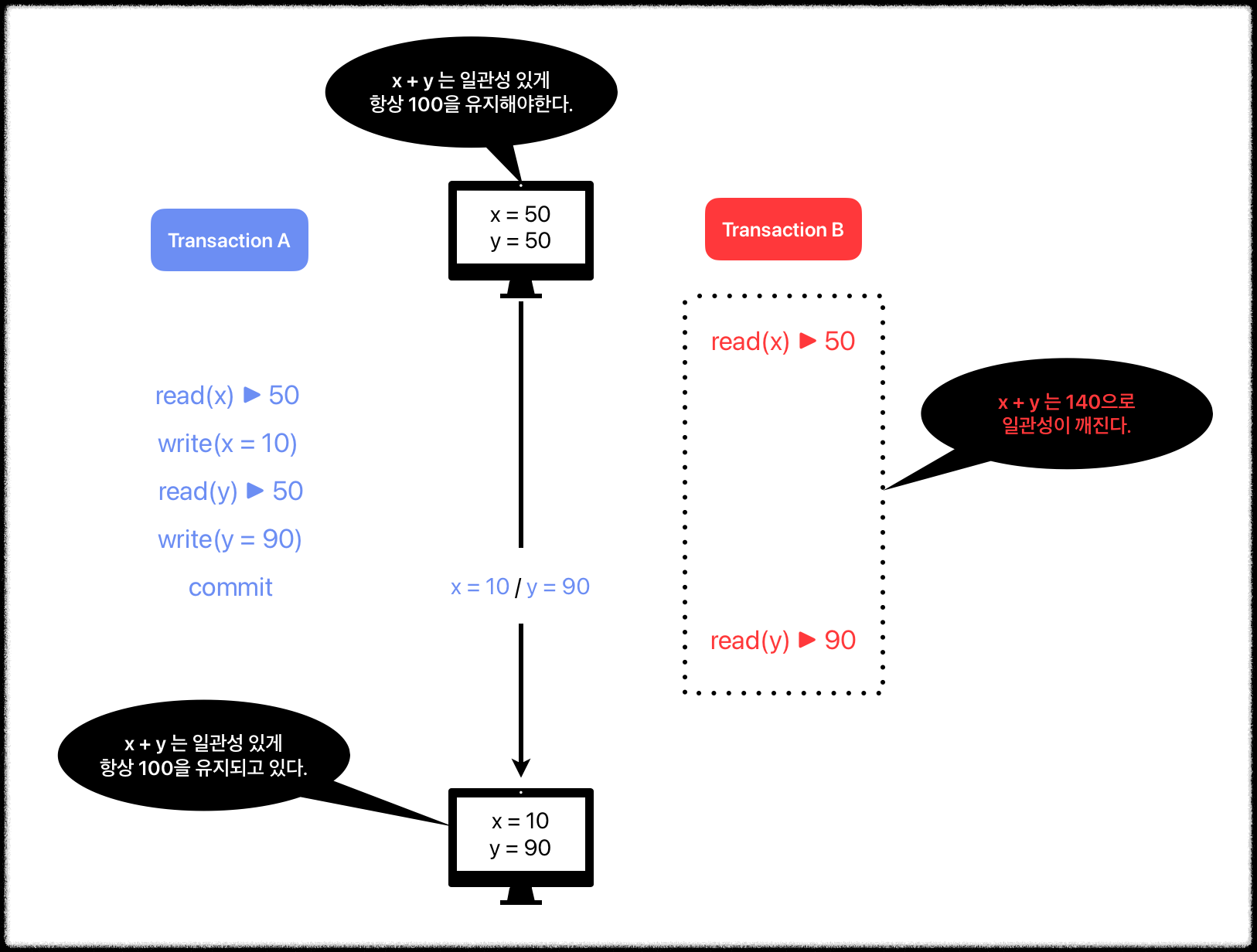
위의 경우에는 commit 되지 않은 경우를 보았고, 이 경우는 tx_a가 커밋을 한 후에 tx_b가 y를 읽고 있다.
여기서도 마찬가지로 x + y 가 140으로 일관성이 있는 읽기를 하고 있지 않음을 확인할 수 있다.
만약 tx_b가 두번의 read를 x에 대해서만 했다면, non-repeatable read와 비슷하게 동작하게 된다.
8. Write skew = 논리적 일관성 없는 데이터 write
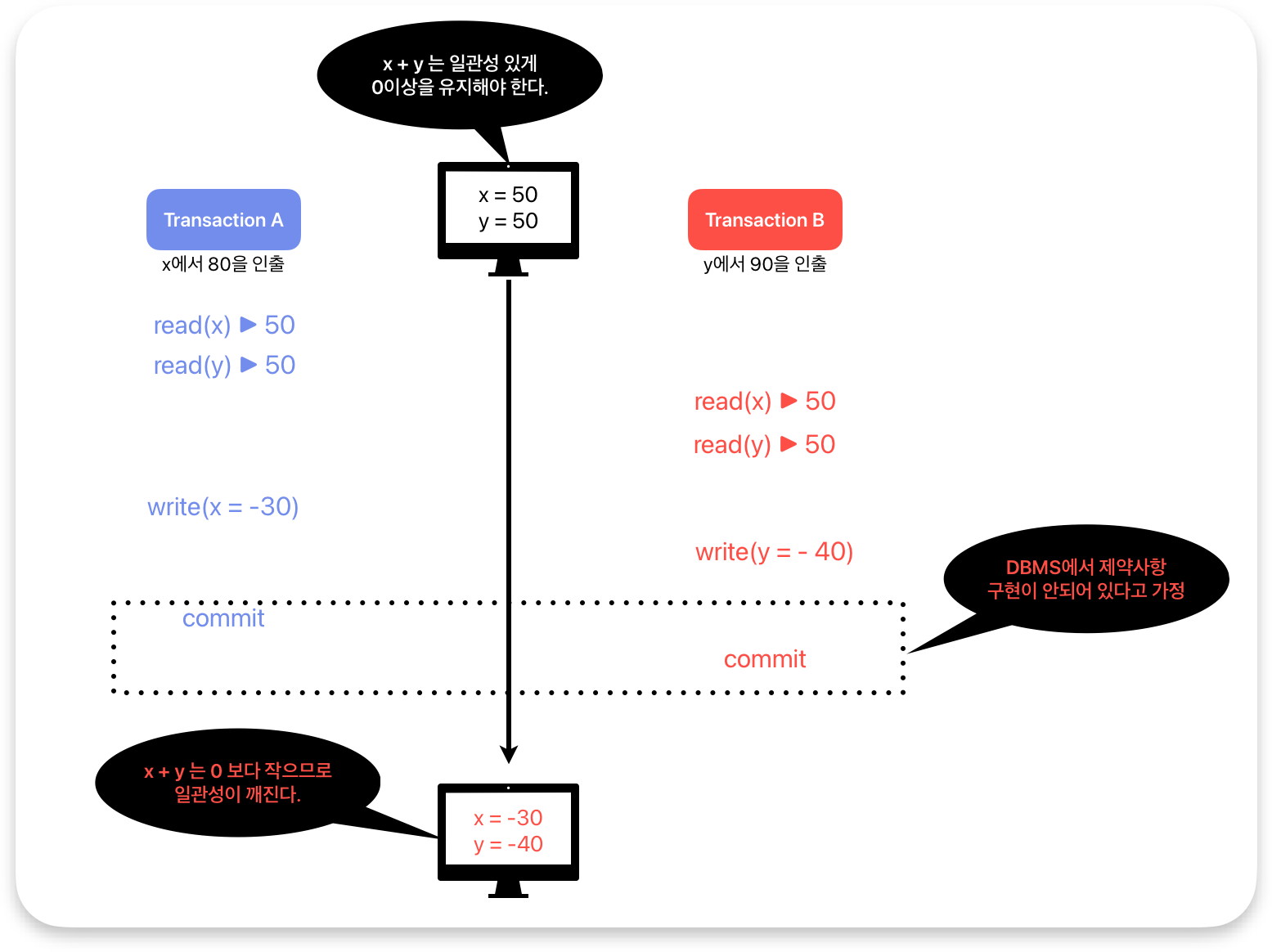
결과적으로 x, y의 합이 0보다 작기 때문에 논리적인 일관성이 깨지게 된다. 이런 현상을 write skew라고 한다.
물론 DBMS에서 제약사항을 잘 적용한다면 이런 문제는 발생하지 않을 것이다.
9. Phantom read (Edition) = 연관된 데이터 그러나 논리적인 결과가 다른 경우
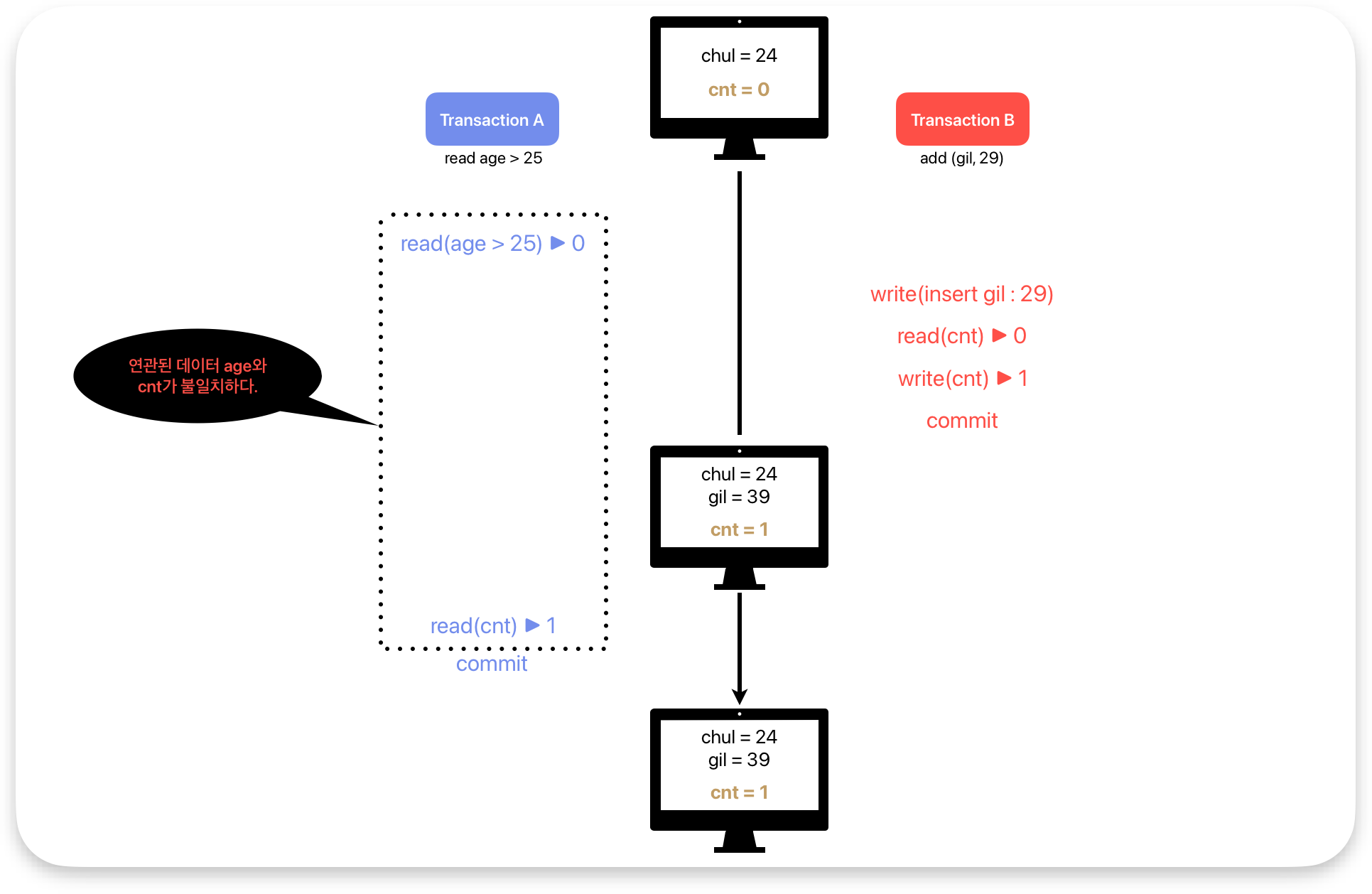
최초에 tx_a가 age가 25 이상인 튜플을 read할 때 결과는 0이였다. 하지만, tx_b가 데이터를 write 한 후
tx_a가 age와 연관된 데이터 cnt를 읽었을 때 결과는 1이였다. 결과적으로 최초에 읽은 데이터와 논리적으로
결과가 불일치하다. 이런 경우도 Phantom read에 포함된다.
❒ 표준 SQL의 isolation level
Isolation level은 일부 이상한 현상은 허용하는 몇 가지 level을 만들어서 사용자가 필요에 따라서
적절하게 선택할 수 있게 하기 위해서 만들어진 것이다. 따라서 애플리케이션 설계자는 isolation level을 통해
전체 처리량 (throghput)과 데이터 일관성 사이에서 어느 정도 거래(trade)를 할 수 있다.

❒ Snapshot Isolation
Snapshot isolation에서는 상업적인 DBMS에서 사용되는 방법을 반영해서 isolation level을 구분하지 않는다.
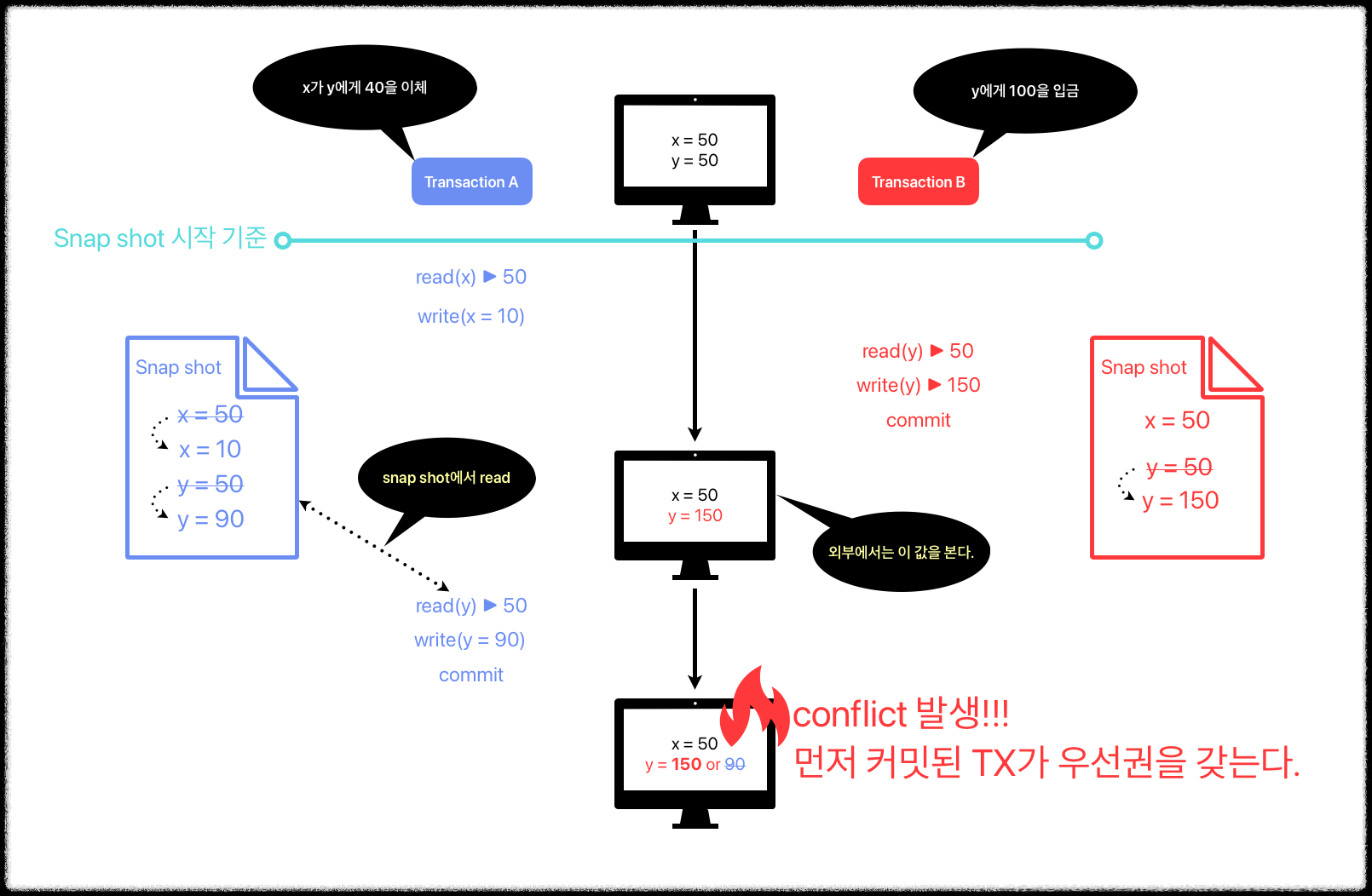
- 우선 Snap shot 시작 기준을 잡는다.
- 모든 트랜잭션들은 commit 전 까지의 write 작업을 snap shot에 기록한다. (변경 사항도 기록된다.)
- 다른 한 쪽에서 커밋 했더라도, sanp shot에서 read한다.
- 외부에서 튜플을 조회할 때는 커밋된 데이터를 조회한다.
- write-write conflict 발생 시, 먼저 커밋된 tx가 우선권을 갖는다. (First-committer win)
Snapshot isolation은 위와 같이 동작하며, MVCC(Multi Version Concurrency Control)의 한 종류이다.
'CS > Database' 카테고리의 다른 글
| MVCC (Multi Version Concurrency Control) (0) | 2024.10.02 |
|---|---|
| Lock을 활용한 concurrency control (0) | 2024.10.02 |
| DB Transaction & Concurreny Control (2) (0) | 2024.09.20 |
| DB Transaction & Concurreny Control (1) (0) | 2024.09.12 |
| B-tree와 DB 인덱스(index) (0) | 2024.09.01 |