
❐ 0. 개요
- 현실 세계에서 데이터는 무한하고(unbounded) 시간이 지나면서 계속(gradually) 유입된다.
- 이번 장에서는 데이터 관리 메커니즘으로 이벤트 스트림을 설명한다.
- 이벤트 스트림은 일과 처리 데이터와는 반대로 한정되지 않고 점진적으로 처리된다.
- 일반적으로 "스트림"은 시간에 흐름에 따라 점진적으로 생산된 데이터를 일컫는다.
❐ 1. 이벤트 스트림 전송
Polling 방식의 한계
- 파일이나 데이터베이스만으로도 생산자와 소비자는 연결될 수 있다.
- 생산자는 자신이 생성한 모든 이벤트를 저장소에 기록
- 소비자는 주기적으로 저장소를 polling하여 마지막 실행 이후 새로 생긴 이벤트를 확인
- 이런 방식은 하루치 데이터를 하루가 끝날 때 처리하는 배치 처리와 유사
- 하지만 polling을 자주 할수록
- 새 이벤트를 실제로 얻는 요청 비율은 낮아짐.
- 즉, 시스템 오버헤드가 커지게 됨. (불필요한 요청을 많이하기 때문)
- 따라서 새 이벤트가 발생했을 때 소비자에게 알림이 전달되는(push) 방식이 더 효율적
- 데이터베이스에도 trigger 기능이 있긴 함.
- 근데 트리거는 기능이 제한적이고 데이터베이스를 설계한 이후에 도입된 개념
🌀 1-1. 메시징 시스템
메시징 시스템
- 새로운 이벤트에 대해 소비자에게 알려주려고 쓰이는 가장 일반적인 방법
- 메시징 시스템을 구축하는 가장 간단한 방법 ➔ 생산자와 소비자 사이에 직접 통신 채널을 사용하는 방식
- 메시징 시스템에서는 다수의 생산자 노드가 동일한 토픽으로 메시지를 전송할 수 있고,
소비자 노드가 토픽 하나에서 메시지를 받아 갈 수 있음.
시스템을 구별하는데 도움이 되는 2가지 질문
- 소비자가 메시지를 처리하는 속도보다, 생산자가 메시지를 전송하는 속도가 더 빠르면?
- 메시지 버리기 / 버퍼링 / 배압
- 노드가 죽거나 일시적으로 오프라인이 된다면 손실되는 메시지가 있을까?
생산자에서 소비자로 메시지를 직접 전달하기 - Direct messaging
- 많은 메시지 시스템은 생산자와 소비자를 네트워크로 직접 통신한다.
- UDP 멀티-캐스트
- ZeroMQ
- ...
- 본래의 설계대로 동작하면 잘 동작함
- 생산자와 소비자가 항상 온라인 상태라고 가정함.
- TCP, UDP, WebSocket 같은 시스템은 이런 상황에서 문제 없이 동작
- 하지만 혀용 가능한 범위가 상당히 제한적이다.
- “네트워크 일시 장애” 정도는 커버하지만
- 생산자 또는 소비자가 오프라인이 되는 경우는 처리하지 못한다
- 네트워크 상에서 재전송을 지원하더라고, 애플리케이션 레벨에서는 모를 수 있음.
- 따라서 메시지가 유실될 수 있는 가능성을 고려해서 애플리케이션 코드를 작성해야 한다.
메시지 브로커 (메시지 큐)
- Direct messaging의 대안으로 널리 사용되는 방법
- 근본적으로 메시지 스트림을 처리하는데 최적화된 데이터베이스의 일종
- 메시지 브로커는 서버로 구동되고 생산자와 소비자는 서버의 클라이언트로 접속함.
- 생산자 ➔ 브로커 ➔ 소비자
- 이 방식에서는 브로커에 데이터가 모이기 때문에 소비자 또는 생산자 노드가 오프라인이여도 쉽게 대처 가능
- 지속성 문제가 브로커로 옮겨갔기 때문
- 브로커가 장애로 중단됐을 때도 메시지를 잃어버리지 않기 위해 디스크 또는 메모리에 메시지를 기록함.
- 소비 속도가 느린 소비자가 있으면 배압을 사용하는 것과 반대로 큐가 제한 없이 늘어나게 함.
- 대기 큐를 사용하면 소비자는 일반적으로 비동기로 동작함.
- 생산자는 메시지 소비 유무를 신경 안 씀
- 물론 큐에 대기중이 메시지가 많으면 쫌 시간이 지나서 처리될 순 있긴 함.
메시지 브로커와 데이터베이스 비교
| 구분 | 데이터베이스 | 메시지 브로커 |
| 삭제 | 데이터를 명시적 삭제해야 함 | 메시지는 소비자에게 전달되면 자동 삭제 |
| 큐 크기 | 저장 공간이 커도 문제 없음 | 작업 집합이 작다고 가정 (작은 큐 크기) |
| 데이터 선택/조회 방식 | SQL, 인덱스, 조건 검색 등 쿼리 중심 | Topic 기반 구독, 패턴 매칭 제공 |
| 질의와 변경 감지 | - 쿼리 결과는 특정 시점(snapshot) 기준 - 이후 변경은 자동 반영되지 않음 (polling 필요) - 정적 질의 위주 | - 데이터 변경 시 자동 알림(push) - 새 메시지가 생기면 구독자에게 전달 - 실시간 알림 중심 |
복수 소비자
➔ 같은 토피에서 메시지를 읽을 때 사용하는 주요 패턴

- 각 메시지는 소비자 중 하나로 전달.
- 따라서 소비자들은 해당 메시지를 처리하는 작업을
공유한다. - 브로커가 메시지를 전달할 소비자를 임의로 지정한다.
- 메시지 처리 비용이 비싸서, 처리를 병렬화 하기 위해
소비자를 추가 하고싶을 때 유용함.

- 각 메시지는 모든 소비자에게 전달된다.
- 여러 독립적인 소비자가 브로드캐스팅된 동일한 메시지를
간섭 없이 청취(tune-in)할 수 있다. - 이것은 같은 입력 파일을 읽어 여러 다른 일괄 처리
작업에서 사용하는 것과 동일
- 위 두가지 패턴은 함께 사용이 가능함.
- 소비가 그룹 A,B가 TopicA를 구독
- 각 그룹에서 모든 메시지 받음.
- 단, 각 메시지를 하나의 노드만 받게 함.
확인 응답과 재전송
- 메시지 브로커는 메시지를 잃어버리지 않기 위해서 확인 응답(acknowledgments)을 사용한다.
- 클라이언트는 메시지 처리가 끝났을 때 브로커에게 명지적으로 알려야 함.
- 브로커가 확인 응답을 받기 전에 클라에서 문제가 생기면 메시지가 처리되지 않았다고 가정
- 그리고 다른 소비자에게 재선송
- 메시지가 실제로 처리됐음에도 네트워크 상에서 확인 응답을 유실할 수 있음.
- 이런 경우를 처리하기 위해 원자적 커밋 프로토콜이 필요함.
- 현실의 분산 트랜잭션에서 ...
로드밸런싱과 결합하면 생기는 문제

- 로드벨런싱과 결합하면 위의 이미지와 같이 메시지 순서에 영향을 미친다.
- 이건 필연적으로 발생하는 문제 (로드벨런싱을 사용하지 않으면 문제를 피할 수 있음.)
🌀1-2. 파티셔닝된 로그
개요
- AMQP/JMS 형식의 메시징 처리는
- 브로커가 확인 응답을 받으면 브로커에서 메시지를 삭제하기 때문에 이미 받은 메시지는 복구할 수 없음.
- 그래서 소비자를 다시 실행해도 동일한 결과를 받지 못함.
- 그리고 기본적으로 메시징 시스템에서 새로운 소비자를 추가하면, 추가한 시점 이후의 메시지부터 받음.
- 데이터베이스의 지속성 있는 저장 방법과 메시징 시스템의 지연시간이 짧은 알림 기능을 조합할 수는 없을까?
➔ 로그 기반 메시지 브로커(log-based message broker)
로그를 사용한 메시지 저장소
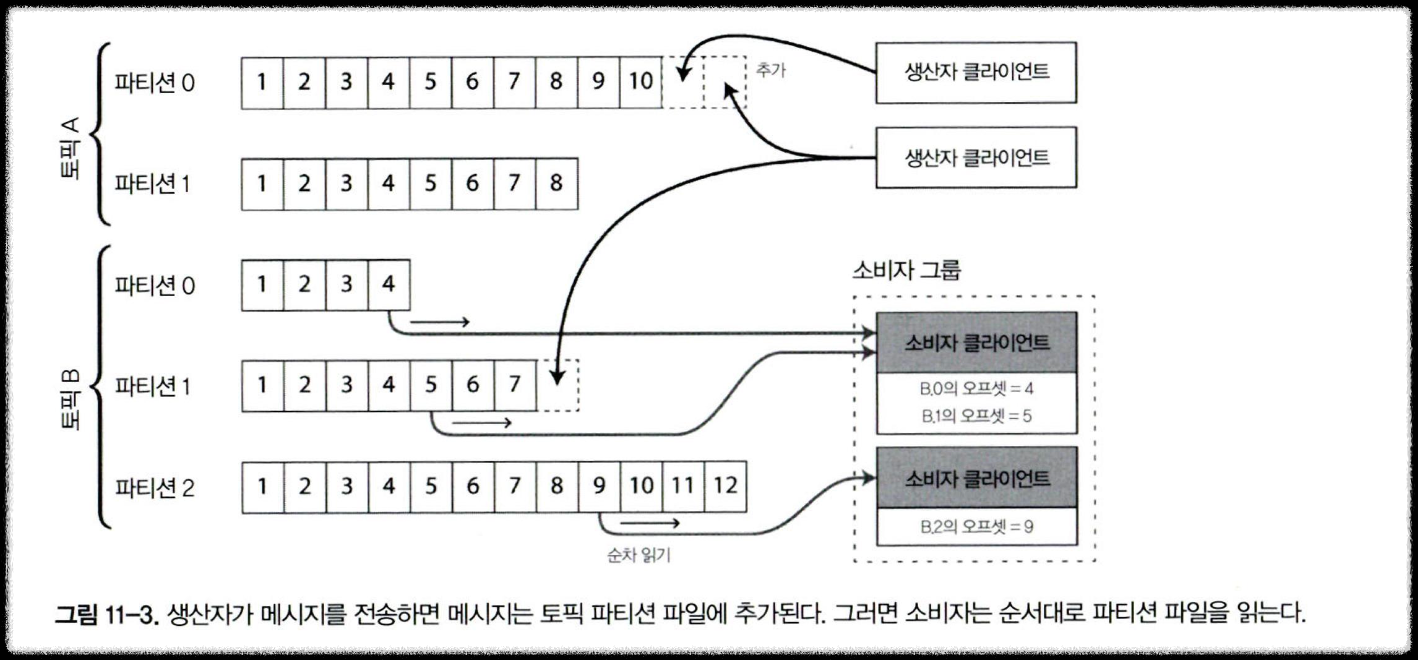
- 생산자가 보낸 메시지는 로그 끝에 추가하고, 소비자는 로그를 순차적으로 읽어 메시지를 받음.
- 소비자가 로그 끝에 도달하면 새 메시지가 추가됐다는 알림을 기다림.
- 디스크 하나를 쓸 때보다 처리량을 높이기 위햇 확장하는 방법으로 로그를 파티셔닝
- 이렇게 하면 각 파티션은 다른 파티션과 독립적으로 읽고 쓰기가 가능한 로그가 됨.
- 토픽은 같은 형식의 메시지를 전달하는 파티션들의 그룹으로 정의한다.
- 각 메시지에는 오프셋(단조 증가하는 순번)이 붙음
- 파티션 안에서는 순서가 보장되지만, 파티션 간에는 순서 보장 없음.
- 대표 예시
- 아파치 카프카, 아마존 키네시스 스트림, 트위터의 분산 로그
로그 방식과 전통적인 메시징 방식의 비교
- 로그 기반 접근법은 소비자가 메시지를 읽어도 로그에서 삭제되지 않음.
- 개별 메시지를 소비자에게 할당하지 않고, 소비자 그룹의 노드들에게 전체 파티션을 할당
- 한 파티션은 순서가 보장되어야 하므로 한 스레드(single-thread)로 순차적으로 처리
- 이런 거친 방식의 로드벨런싱(Coarse-grained Load Balancing) 방법은 몇 가지 불리한 면이 있다.
- 파티션 수 한계 : 소비자 수는 파티션 수보다 많을 수 없음.
- Head-of-line-blocking : 앞에서 지연되면 뒤 파티션들도 모두 지연
- 언제 뭘 쓰면 되냐
- JMS/AMQP 방식의 메시지 브로커
- 메시지 순서는 중요하지 않은데, 처리 비용이 비싸고 병렬화 처리하고 싶은 경우
- 로그 기반 접근법
- 메시지 순서가 중요 + 메시지 처리 속도 빠름 + 처리량 많음
- JMS/AMQP 방식의 메시지 브로커
소비자 오프셋
- 소비자 오프셋을 사용하면 메시지 처리 현황을 알기 쉽다.
- 따라서 브로커는 모든 개별 메시지마다 보내는 확인 응답을 추적할 필요가 없다.
- 이 방법을 사용하면
- 추적 오버헤드가 감소
- 일괄 처리와 파이프라이닝을 수행할 수 있는 기회를 제공 ➔ 로그 기반 시스템의 처리량 향상
- 데이터베이스 복제에 사용되는 로그 순차 번호(log sequence number)와 상당히 유사함.
- 메시지 브로커는 데이터베이스의 리더처럼 동작하고 소비자는 팔로워처럼 동작함.
- 소비자 노드에 장애가 발생하면, 소비자 그룹 내 다른 노드에 장애가 난 소비자의 파티션을 할당
- 그리고 마지막 기록된 오프셋부터 메시지를 처리하기 시작.
디스크 공간 사용
- 로그를 추가하다보면 결국 디스크 용량을 다 쓰게 됨.
- 디스코 용량을 재사용하기 위해서 오래된 조각을 삭제하거나 보관 저장소로 이동
- 근데 소비자의 속도가 생산자 보다 느리면 메시지가 유실될 수 있음.
- Kafka는 로그를 무한히 저장하지 않고, 시간이 지나면 오래된 로그(segment)는 자동으로 삭제
- 결과적으로 로그는 크기가 제한된 버퍼로 구현
- 이런 버퍼는 원형 버퍼 또는 링 버퍼라고 함.
소비자가 생산자를 따라갈 수 없을 때
- 앞에서 소비자가 느릴 때 대처할 수 있는 세 가지 방법을 이야기 했었음 (버리기 / 버퍼링 / 배압)
- 로그 기반 접근법은 고정 크기의 버퍼를 사용하는 버퍼링 형태.
- 소비자가 뒤쳐지면 필요한 메시지를 읽지 못 할 수 있음.
- 버퍼는 충분히 크다면,
- 운영자가 느린 소비자를 수정해서 메시지 손실이 발생하기 전까지 따라잡도록 할 수 있음.
- kafka는 버퍼는 메모리 기반 큐보다 훨씬 큼 (수GB ~ 수 TB)
오래된 메시지 생성
- 로그 기반 접근 법도 오래된 메시지를 읽을 수 있음.
- 메시지를 파일에 append하고, 소비자가 읽을 때 그 메시지를 삭제하지 않음.
- 오직 변하는건 소비자의 오프셋
- 여기서 오프셋은 소비자의 관리 아래 있기 때문에, 원하는대로 변경할 수 있음.
- 이런 특성 때문에 로그 기반 메시징은 이전 장의 배치 처리와 비슷
- 즉, 입력 데이터(로그)를 그대로 두고,
소비자는 그걸 읽어 결과를 별도로 만들어내는 구조.(파생된 결과 데이터)
- 이런 구조 덕분에,
- 실험(코드 변경)을 자유롭게 할 수 있음.
- 에러나 버그 발생시 복구도 쉬움
- 조직 내 여러 데이터 흐름(dataflow)을 통합하는 데 매우 유용
근데 시간 지나면 삭제한다고 했는데?
- Kafka는 보존(retention) 정책에 따라 오래된 로그(segment)를 자동으로 삭제
- Kafka 자체는 “단기 버퍼”로 쓰고, 장기 보존은 데이터 레이크(HDFS/S3)에 저장하는 게 일반적
❐ 2. 데이터베이스와 스트림
🌀 2-1. 시스템 동기화 유지하기
데이터베이스와 스트림
- 데이터베이스는 “현재 상태”를 저장
- 스트림은 “시간의 흐름에 따라 일어난 사건(event)”을 저장
이중쓰기 문제
- 둘 중 하나만 성공하거나 실패할 수 있음
- 이런 경우 두 시스템의 데이터 불일치(inconsistency) 가 발생
- 이런 문제를 완벽히 해결하려면 원자적 커밋(atomic commit) 이나 2PC 같은 고비용 트랜잭션이 필요
- 단일 리더 복제 구조에서는 리더가 쓰기 순서를 정해 덜 복잡하지만,
리더가 여러 개이거나 없는 구조에서는 충돌이 자주 발생
🌀 2-2. 변경 데이터 캡처
변경 데이터 캡처(change data capture, CDC)
- CDC는 데이터베이스에 기록하는 모든 데이터의 변화를 관찰해
다른 시스템으로 복제할 수 있는 형태로 추출하는 과정 - 데이터가 기록되자마자 변경 내용을 스트림으로 제공할 수 있으면 특히 유용함.

- 위의 예시에서 검색 색인 뿐만 아니라 데이터 웨어하우스도 "변경 스트림의 소비자"임.
변경 데이터 캡처의 구현
- “검색 인덱스나 "데이터 웨어하우스" 같은 시스템은
원본 데이터베이스의 로그를 소비하여 만들어지는 파생(derived) 데이터 시스템 - CDC는 레코드 시스템의 정확한 데이터 복제본을 가지게 하기 위해 레코드 시스템에 발생하는
모든 변경 사항을 파생 데이터 시스템에 반영하는 것을 보장하는 메커니즘 - CDC는 본질적으로 변경 사항을 캡처할 DB 하나를 리더로 하고 나머지를 팔로워로 한다.
- CDC를 구현하는데 DB trigger를 사용하기도 함.
- 하지만 이 방식은 전반적으로 취약하고, 성능 오버헤드가 상당함.
- 메시지 브로커와 동일하게 비동기 방식으로 동작
- 그렇기 때문에 어떠한 설계로 인해 느린 소비자가 추가되어도 레코드 시스템에 미치는 영향은 없음.
- 하지만 복제 진연의 문제가 발생하는 단점이 있음.
초기 스냅숏
- 모든 변경 사항을 영구적으로 보관하는 일은 디스크 공간이 많이 필요하고,
로그를 재생하는 작업도 너무 오래 걸림. 그래서 로그를 적당히 잘라야 함. - 일부 CDC 도구는 스냅숏 기능을 내장하고 있으나, 수작업으로 해야하는 CDC 도구도 있음.
로그 컴팩션
- 앞에서 다룬 내용
- 로그 컴팩션 과정을 통해 중복을 제거하고, 각 키에 대해 가장 최근에 갱신된 내용만 유지
- 컴팩션과 병합 과정은 백그라운드로 진행
- 이 과정 덕분에
- 로그에 데이터베이스에 있는 모든 키의 최신 값이 존재하는 것이 보장됨.
- 따라서 검색 색인과 같은 파생 데이터 시스템을 재구축할 때마다 새 소비자는
컴팩션된 로그 토픽의 오프셋 0부터 시작해서 모든 키를 스캔하면 됨.
- 아파치 카프카는 로그 컴팩션 기능을 제공함.
- 메시지 브로커는 일시적 메시징뿐만 아니라 지속성 있는 저장소로도 사용 가능함
- (후반부에 자세히 다룰 예정)
변경 스트림용 API 지원
- 최근 데이터베이슨는 리버스 엔지니어링을 통해 점진적으로 변경 스트림을 기본 인터페이스로 지원하기 시작
- 예) 리싱크DB는 질의 결과에 변경이 있을 때 알림을 받을 수 있게 구독이 가능한 질의를 지원하는 등...
🌀 2-3. 이벤트 소싱
이벤트 소싱
- DDD 커뮤니티에서 개발한 기법
- CDC와 유사하게 애플리케이션 상태 변화를 모두 변경 이벤트 로그로 저장한다.
- 차이점은 이 아이디어를 적용하는 추상화 레벨이 다르다는 점
CDC vs 이벤트 소싱
- CDC : DB 내부의 변경 로그를 읽어서 데이터 변화를 외부로 전달하는 방식
- 데이터베이스를 자유롭게 수정 가능한(mutable) 방식으로 사용
➔ INSERT / UPDATE / DELETE 를 마음대로 수행할 수 있다. - 데이터베이스의 변경 로그(replication log)를 읽어서 변경 내용을 추출
➔ DB에 실제로 기록된 순서를 그대로 반영할 수 있어서 경쟁 조건이 생기지 않는다. - 애플리케이션은 CDC가 동작 중이라는 사실을 몰라도 된다.
➔ 즉, DB는 평소처럼 사용하고, CDC는 백그라운드에서 로그를 감시
- 데이터베이스를 자유롭게 수정 가능한(mutable) 방식으로 사용
- 이벤트 소싱 : 애플리케이션에서 발생한 사건을 불변 이벤트로 기록하는 설계 방식
- 애플리케이션 로직 자체가 이벤트 기반으로 설계
➔ 이벤트들을 불변(immutable) 형태로 이벤트 로그에 기록한다. - 이벤트 저장소는 “append-only” 구조이며, 수정/삭제 금지.
- 이벤트는 낮은 수준의 데이터 변경이 아니라, 비즈니스 수준에서 실제 일어난 일을 표현
- 애플리케이션 로직 자체가 이벤트 기반으로 설계
이벤트 소싱의 특징
- 모든 상태 변화는 이벤트 로그로 남는다.
- "회원가입됨”, “주문됨”, “결제됨”, “배송완료됨” 같은 이벤트들이 시간순으로 기록됨.
- 데이터는 절대 수정하거나 삭제하지 않는다.
- 변경이 생기면 “이전 상태를 취소하는 새 이벤트”를 추가함.
- 즉, 로그를 Append 방식으로만 저장
- 현재 상태는 이벤트를 전부 재생(Replay)하여 도출함.
- 시스템 장애나 버그가 생겨도 이벤트를 다시 읽어 현재 상태를 재구성하기 용이함.
- 디버깅 및 변경 추적이 용이하다.
이벤트 로그에서 현재 상태 파생하기
- 이벤트 소싱을 사용하는 애플리케이션은
- 시스템에 기록한 데이터를 표현한 이벤트 로그를 가져와
사용자에게 보여주기에 적당한 애플리케이션 상태로 변환해야 함. - 이 변환 과정은 결정적(deterministic) 과정이어야 함. (다시 수행해도 똑같은 상태여야 하기 때문)
- 일반적으로 이벤트 로그에서 파생된 현재 상태의 스냅숏을 저장하는 메커니즘이 있음.
- 따라서, 매번 전체 로그를 반복해서 재처리할 필요는 없음.
- 시스템에 기록한 데이터를 표현한 이벤트 로그를 가져와
CDC와 이벤트 소싱의 로그 관리 방식 차이
- CDC
- 데이터베이스의 상태 변경을 그대로 반영
- 즉, “기본키 기준으로 가장 최신 상태” 만 유지하면 된다.
- 이전 상태(이전 이벤트)는 로그 컴팩션을 통해 지워진다.
- 불필요한 옛 버전은 버려도 현재 상태 복원이 가능함.
- 이벤트 소싱
- 이벤트 소싱은 사용자의 의도나 행동 자체를 이벤트로 기록
- 각 이벤트는 과거 기록을 덮어쓰지 않으며, 시스템 상태를 복원하려면 모든 이벤트의 전체 히스토리가 필요
- 따라서 로그 컴팩션은 불가능하다. (이전 이벤트도 시스템의 의미 있는 일부이기 때문)
명령과 이벤트
- 이벤트 소싱의 철학은 이벤트와 명령(command)를 구분하는데 있다.
- 사용자 요청이 처음 왔을 때 ➔ 명령
- 이 시점에 명령이 실패할 수 있음.
- 명령에 대한 무결성이 검증되고 승인되면, 명령은 지속성 있는 불변 이벤트가 됨.
- 이벤트는 생성 시점에 사실(fact)가 된다.
- 이벤트 스트림의 소비자는 이벤트를 거절하지 못한다.
- 소비자가 이벤트를 받는 시점에는 이벤트는 이미 불변 로그의 일부
- 따라서 유효성 검증은 이벤트로 바뀌기 이전 단계(명령 단계)에서 동기적으로 수행해야 함.
- 비동기 처리로 유효성을 검사하기
- 좌석 예약처럼 여러 사용자가 동시에 같은 자원을 요청하는 경우를 예로 들었음.
- 먼저 “가예약”을 이벤트 발행
- 이후에 유효성 검증 후 문제가 없을 때 “확정 이벤트”를 발행
🌀 2-4. 상태와 스트림 그리고 불변성
불변성 원리 덕분에...
- 입력 파일에 손상을 주지 않고, 기존 입력 파일에 얼마든지 실험적 처리 작업을 수행할 수 있음.
- 이 원리가 이벤트 소싱과 CDC를 매우 강력하게 만들어줌.
- 그런데 데이터베이스는 수정/삭제를 지원하는데 어떻게 불변성과 어울림?
변경된 상태는 시간의 흐름에 따라 변한 이벤트의 마지막 결과
- 상태가 어떻게 바뀌었든 항상 이런 변화를 일으킨 일련의 이벤트가 있음.
- 변경 로그를 지속성 있게 저장한다면 상태를 간단히 재생성할 수 있는 효과가 있음.
불변 이벤트의 장점
- 회계 원장(ledger)처럼 신뢰 가능한 기록 유지
- 즉, “언제, 어떤 변화가 있었는가” 를 신뢰성 있게 남길 수 있음.
- 오류 복구 및 감사(audit)에 강함
- 잘못된 데이터가 생겨도 기존 기록을 수정하지 않고 “오류를 보정하는 새로운 이벤트”를 추가
- 코드 실수나 데이터 오염이 발생했을 때, 불변 로그를 통해 과거 상태를 재현하기가 훨씬 쉬워짐
- 데이터 손실 및 복구 위험 감소
- 잘못된 데이터가 저장되어도 이전 이벤트가 보존되어 있어 복구 가능
- 분석 및 추적에 유용한 풍부한 히스토리
- 불변 이벤트는 단순히 “현재 상태”뿐 아니라 사용자의 행동 패턴, 취소된 행동의 흔적까지 포함
동일한 이벤트 로그로 여러 가지 뷰 만들기
- 불변 이벤트 로그에서 가변 상태를 분리하면 동일한 이벤트 로그로 다른 여러 읽기 전용 뷰를 만들 수 있다.
- Druid는 카프카로부터 직접 데이터를 읽어 처리
- Pistachio는 분산 키-값 저장소로 카프카를 커밋 로그처럼 사용
- 카프카 커넥트 싱크는 카프카에서 여러 데이터베이스와 색인에 데이터를 내보낼 수 있음.
- 이벤트 로그를 기반으로 하면 시스템을 바꾸거나 확장하기 훨씬 쉽다.
- 새로운 기능이 필요하면?
- 기존 DB는 변경하지 않고, 이벤트 로그를 읽어서 적절한 "읽기 전용 뷰" 만들면 됨
- 이벤트 로그는 원본 데이터의 근거(ground truth) 이기 때문에,
- 새로운 시스템은 기존 시스템의 로그를 그대로 읽어 독립적으로 실행할 수 있음.
- 결국 신/구 버전이 같이 공존할 수 있고, 점진적으로 구 버전을 없앨 수 있음.
- 새로운 기능이 필요하면?
- 대표적인 응용의 예로 CQRS가 있음
- DB 스키마, 색인(index), 저장 방식이 “쓰기 성능”과 “읽기 편의성”을 동시에 만족시키기 어려움
- 따라서, 데이터를 읽기와 쓰기로 분리하면 시스템을 더 유연하고 효율적으로 설계할 수 있음.
동시성 제어
- 이벤트 소싱과 CDC의 가장 큰 단점은 이벤트 로그의 소비가 대게 비동기로 이뤄진다는 것.
- 해결책
- 읽기 뷰의 갱신과 로그에 이벤트를 추가하는 작업을 동기식으로 수행하는 방법
- 이벤트 로그로 현재 상태를 만드는 방법
- 이벤트 로그와 애플리케이션 상태를 같은 파티션 단위로 설계하는 방법
불변성의 한계
- 많은 시스템은 불변 구조를 사용한다.
- Git, Mercurial, Fossil 같은 버전 관리 시스템
- 이들은 과거의 모든 변경 이력(history) 을 보존하기 위해 불변 데이터를 사용한다.
- 불변성은 데이터의 일관성, 감사 가능성, 복구 용이성 측면에서 매우 유용하다.
- 하지만 “모든 데이터를 영구적으로 불변”으로 두는 것은 현실적으로 어려움
- 저장소 용량과 성능 문제
- 데이터가 계속 쌓이기만 하고 삭제되지 않으면,
저장소가 점점 커져서 관리 비용과 성능 문제가 발생할 수 있다. - 특히 자주 갱신되는 데이터셋의 경우,
불변 이력을 모두 유지하면 공간 낭비와 검색 성능 저하로 이어질 수 있다. - 압축이나 가비지 컬렉션을 해야 하지만, 이 또한 복잡하고 비용이 큼
- 데이터가 계속 쌓이기만 하고 삭제되지 않으면,
- 법적 / 관리적 이유로 삭제가 필요한 경우
- 이런 경우에는 “삭제 이벤트를 추가하는 것”으로 해결되지 않는다.
왜냐하면 기존 데이터가 여전히 로그 안에 존재하기 때문. - 첨부터 기록하지 않았던 것 처럼 해야함.
- 이런 경우에는 “삭제 이벤트를 추가하는 것”으로 해결되지 않는다.
- 저장소 용량과 성능 문제
❐ 3. 스트림 처리
스트림을 처리하는 3가지 선택지
- 이벤트에서 데이터를 꺼내서 저장소 시스템에 기록하고, 데이터를 질의
- 이벤트를 사용자에게 직접 전달
- 하나 이상의 입력 스트림을 처리해 하나 이상의 출력 스트림을 생산 (이번장에서 살펴볼 부분)
🌀 3-1. 스트림 처리의 사용 (Uses of Stream Processing)
모니터링
- 주로 특정 상황이 발생하면 조직에 경고를 해주는 모니터링 목적으로 오랜 기간 사용돼 왔음.
- 그러나 시간이 지나면서 다른 용도로 스트림 처리를 사용하는 사용자들이 나타나기 시작함.
복잡한 이벤트 처리 (complex event processing, CEP)
- 1990년대에 이벤트 스트림 분석용으로 개발된 방법
- 특정 이벤트 패턴을 검색해야 하는 애플리케이션에 특히 적합
- 실시간으로 발생하는 여러 이벤트 스트림을 분석하여,
특정한 패턴이나 조건이 충족될 때 새로운 "복합 이벤트"를 생성하는 시스템 - 감지한 이벤트 패턴을 묘사하기 위해 종종 SQL과 같은 고수준 선언형 질의 언어를 사용하기도 함.
- 이 시스템에서는 질의는 오랜 기간 저장되고, 입력 스트림으로 부터 들어오느 이벤트는 지속적으로
질의를 지나 흘러가면서 이벤트 패턴에 매칭되는 질의를 찾는다. - 에스퍼, 아파마, SQL스크립트 등이 있음.
스트림 분석
- 연속한 특정 이벤트 패턴을 찾기보단, 대량의 이벤트를 집계하고 통계적 지표를 뽑는 것을 우선함.
- ex. 특정 유형의 이벤트 빈도 측정, 특정 기간에 걸치 값의 이동 평균 계산...
- 일반적으로 이런 통계는 고정된 시간 간격 기준으로 계산한다.
- 집계 시간 간격 = 윈도우(window)
- 최적화를 위해 "확률적 알고리즘"을 사용하기도 함.
- 아파치 스톰, 스파크 스트리밍, 카프카 스트림 등이 있음.
구체화 뷰 유지하기
- 이벤트 소싱에서 애플리케이션 상태는 이벤트 로그를 적용함으로써 유지함.
- 이때 애플리케이션의 상태로 "구체화 뷰"라고 할 수 있음.
- 구체화 뷰를 만들기 위해서는 잠재적으로 임의의 시간 범위에 발생한 모든 이벤트가 필요함.
- 따라서 모든 이벤트가 필요함. ➔ 시작 시점까지 늘려진 윈도우가 필요함.
- 스트림 처리 시스템이라면 이론적으로는 모두 구체화 뷰를 유지하는 데 쓸 수 있다.
- 하지만, materialized view 유지에는 이전 모든 이벤트의 상태를 계속 기억하고 갱신하는 능력이 필요하다.
- 반면 많은 분석 중심 스트림 처리 시스템은 “윈도우 기반(한정된 기간)” 데이터만 처리하도록
설계되어 있기 때문에, 이런 영구 상태 유지 요구사항과는 설계 철학이 충돌한다.
스트림 상에서 검색하기
- 복잡한 기준을 기반으로 개별 이벤트를 검색해야 하는 경우도 있음.
- 전통적인 검색 엔진은 먼저 문서를 indexing하고 index를 통해 질의를 실행
- 반대로 스트림 검색은 처리 순서가 반대임.
- 질의를 먼저 저장함. 그리고 질의를 지나가면서 실행됨.
- 즉, “아직 저장되지 않은, 실시간으로 흘러들어오는 데이터”를 계속 감시하면서 조건이 충족되면 즉시 결과를 생성
메시지 전달과 RPC
- 앞에서 메시지 전달 시스템을 RPC 대안은로 사용할 수 있다고 했음. (139쪽)'
- 메시지 전달 시스템이 RPC처럼 사용될 수 있지만, 스트림 처리와는 다른 특성을 가짐.
- 액터 프레임워크는 메시지 기반 동시성 모델이지만, 데이터 영속성 측면에서는 제한적.
- 스트림 처리는 데이터 흐름 전체를 지속적으로 관리하는 반면,
RPC는 요청-응답(request-response) 중심으로, 일시적인 통신에 가깝다. - 물론 액터 프레임워크를 이용한 스트림 처리도 가능하긴 함.
- 그러나 액터 프레임워크는 장애 상황에서 메시지 전달을 보장하지 않기 때문에
추가적인 재시도 로직을 구현하지 않으면, 처리에 내결함성을 보장하지 못함.
- 그러나 액터 프레임워크는 장애 상황에서 메시지 전달을 보장하지 않기 때문에
🌀 3-2. 시간에 관한 추론 (Reasoning About Time)
➔ (특히 분석 목적으로 사용할 때) 스트림 처리자는 종종 시간을 다뤄야할 때가 있다.
이벤트 시간 대 처리 시간
- 처리가 지연되는 데는 많은 이유가 있음.(큐 크기, 네트워크 결함 등등)
- 메시지가 지연되면 메시지 순서를 예측하지 못할 수도 있다.
- 이벤트 시간과 처리 시간을 혼동하면 좋지 않은 데이터가 만들어짐.

준비 여부 인식
- 이벤트를 시간 단위로 윈도우(Window)로 묶어 처리할 때 생기는 문제
- 현재 윈도우에 속한 모든 이벤트가 도착했는지 확신할 수 없다는 점
- 윈도우를 이미 종료한 후에 도착한 낙오자(straggler) 이벤트를 처리할 방법이 필요함
- 낙오자 이벤트를 무시하기
- 정상적인 상황에서는 늦게 도착하는 이벤트의 비율이 매우 적기 때문.
- 하지만 만약 낙오가 많아지면 경고를 보내거나 추적할 수 있다.
- 수정 값을 발행하기
- 늦게 도착한 이벤트를 포함해 다시 윈도우를 계산(갱신)
- 그에 따라 이전 출력 결과를 취소하거나 보정
- 낙오자 이벤트를 무시하기
- 일부 이벤트는 네트워크 지연이나 장비 문제로 늦게 도착할 수 있음.
- 따라서 시스템은 “언제 윈도우가 완전히 끝났다고 선언할지”를 판단하기 위해
타임아웃이나 특수 메시지(‘더 이상 이전 타임스탬프는 없다’는 신호) 를 사용할 수도 있음. - 하지만 이 방식은 생산자가 이런 신호를 추가해야 하므로 복잡도가 높음.
- 따라서 시스템은 “언제 윈도우가 완전히 끝났다고 선언할지”를 판단하기 위해
어쨋든 어떤 시계를 사용할 것인가.
- 이벤트의 타임스탬프는 모바일 장치 로컬 시계를 따르는, 실제 사용자와 상호작용이
발생했던 실제 시각이어야 함. - 하지만 우연히 잘못된 시간이 설정됐을 가능성이 있기 때문에 사용자가 제어하는 장비의
시계를 항상 신뢰하기는 어려움. - 잘못된 장치 시계를 조정하는 한 가지 방법은 세 가지 타임스탬프를 로그로 남기는 것
- 이벤트가 발생한 시간 (장치 시계를 따른다)
- 이벤트를 서버로 보낸 시간 (장치 시계를 따른다)
- 서버에서 이벤트를 받은 시간 (서버 시계를 따른다)
- 2번과 3번의 타임스탬프 차이를 구하면 장치 시계와 서버 시계 간의 오프셋을 추정할 수 있음.
- 이때 필요한 타임스탬프 정확도에 비해 네크워크 지연은 무시할 만하고,
이벤트가 발생한 시간과 이벤트를 서버로 보낸 시간 사이에는 장치 시계 오프셋이
변하지 않았다고 가정 - 그러면 계산한 오프셋을 이벤트 타임스탬프에 적용해 이벤트가 실제로 발생한 시간을 추정할 수 있음.
- 이때 필요한 타임스탬프 정확도에 비해 네크워크 지연은 무시할 만하고,
윈도우 유형
➔ 윈도우 기간을 어떻게 정의할지 결정해야 함
- 텀블링 윈도우
- 고정된 크기의 윈도우
- 모든 이벤트는 정확히 한 윈도우에 속함.
- ex. {10시03분00초, 10시03분59}
- 홉핑 윈도우
- 고정된 크기의 윈도우
- 결과를 매끄럽게 만들기 위해 윈도우를 중첩할 수 있음.
- 1분 크기의 홉을 이용하는 5분 윈도우 예시
- A1윈도우 : "10시03분00초~10시07분59초"
- A2윈도우 : "10시04분00초~10시08분59초"
- 슬라이딩 윈도우
- 각 시간 간격 사이에서 발생한 모든 이벤트를 포함
- 시간 기준으로 정렬한 이벤트를 버퍼에 유지하고 이벤트가 만료되면
윈도우에서 제거하는 방식으로 구현할 수 있음.
- 세션 윈도우
- 고정된 기간이 없음
- 대신 같은 사용자가 짧은 시간 동안 발생시킨 모든 이벤트를 그룹화해서 세션 윈도우를 정의함.
- 그리고 일정 시간이 지나 사용자가 비활성되면 윈도우 종료
- 웹사이트 분석을 할 때 흔히 필요
🌀 3-3. 스트림 조인
3가지 조인 유형
- 스트림 상에는 새로운 이벤트가 언제든 나타날 수 있기 때문에,
- 스트림 상에서 수행하는 조인은 일괄 처리 작업에서 수행하는 조인보다 훨씬 어려움.
- 3가지 유형
- 스트림-스트림 조인
- 스트림 테이블 조인
- 테이블-테이블 조인
스트림-스트림 조인 (윈도우 조인)
- 웹사이트의 검색 기능에서 사용자가 입력한 검색 이벤트와 그 결과를 클릭한 클릭 이벤트를
연결(조인)하여 사용자의 검색 ➔ 클릭 행동을 분석하는 방식. - 적절한 윈도우 선택이 필요한 이유
- 클릭이 항상 발생하지 않음.
- 검색 이벤트와 클릭 이벤트는 시간 차이가 일정하지 않음.
- 네트워크 지연으로 이벤트 순서가 바뀔 수도 있음.
- 이런 유형의 조인을 구현하려면 스트림 처리가 상태(state)를 유지해야 함.
- 예를 들면, 모든 이벤트를 세션 ID로 색인
스트림 테이블 조인 (스트림 강화)
- 사용자 활동 이벤트 스트림과 사용자 프로필 데이터베이스(테이블)를 결합하는 방식
- 스트림의 각 이벤트에 테이블 정보를 추가해 이벤트를 “강화(enriching)” 하는 형태
- 수행 방법
- 스트림 처리기는 들어오는 활동 이벤트(스트림)를 받는다.
- 각 이벤트의 사용자 ID를 기준으로 데이터베이스를 조회한다.
- 데이터베이스에서 프로필 정보를 가져와 이벤트에 추가한다.
- 이렇게 강화된 이벤트를 출력한다.
- 또 다른 방법은 네트워크 왕복 없이 질의하도록 스트림 처리자 내부에 DB 사본을 적재하는 것
- 스트림은 시간이 흘러가면서 DB 내용이 변할 가능성이 높음.
- 따라서 DB 로컬 복사본을 최신 상태로 유지해야 함.
- 이 문제는 CDC를 사용하면 해결 가능함.
- 스트림-스트림 조인과 매우 비슷함.
- 가장 큰 차이점은 테이블 조인을 할 때, 테이블 변경 로그 스트림 쪽은
"시작 시간"까지 이어지는 윈도우를 사용하며 레코드의 새 버전으로 오래된 것을 덮어씌운다.
테이블 테이블 조인 (구체화 뷰 유지)
- 조인 결과를 지속적으로 유지하고 갱신해야 하는 스트림 기반 “구체화 뷰 유지”와 같다.
- 단순 조회가 아니라 변화가 발생할 때마다 조인 결과(타임라인 캐시)를 실시간으로 갱신하는 과정
조인의 시간 의존성
- 위에서 본 세 가지 조인 유형의 공통점 ➔ 특정 상태를 유지함
- 시간에 따라 변하는 상태를 조인해야 한다면 어느 시점을 조인에 사용해야 할까?
- 예시) 세율
- 복수 개의 스트림에 걸친 이벤트 순서가 결정되지 않으면 조인도 비결정적
- 이 문제를 데이터 웨어하우승는 천천히 변하는 차원(slowly changing dimension, SCS)라 함.
- 이 문제는 흔히 조인되는 레코드의 특정 버전을 가리키는데 유일한 식별자를 사용해 해결함.
🌀 3-4. 내결함성
내결함성
- 스트림 처리의 핵심 과제: 장애가 발생해도 결과가 중복되거나 누락되지 않게 하는 것.
- 일괄 처리(예: MapReduce)는 태스크 단위로 명확한 재처리 경계가 존재하기 때문에
실패 후 재시작해도 동일한 결과를 얻을 수 있다. - 이러한 특성을 정확히 한 번 시맨틱스(Exactly-once semantics) 라고 하며,
실제 의미는 “결과적으로 한 번만 반영(effectively-once)”이다.- 즉, 태스크가 여러 번 실행되더라도 출력 결과는 정확히 한 번만 나타나야 한다.
- 스트림 처리에서도 동일한 문제가 있지만,
- 실시간성 요구로 인해 태스크가 끝날 때까지 기다릴 수 없기 때문에
다른 방식의 내결함성 설계가 필요함.
- 실시간성 요구로 인해 태스크가 끝날 때까지 기다릴 수 없기 때문에
마이크로 일괄 처리와 체크포인트
- 스트림을 짧은 구간(예: 1초 단위)으로 잘라 일괄 처리하듯 다루는 방법.
- 마이크로 일괄 처리(microbatching)
- 특징
- 일반 배치보다 빠르지만, 완전 실시간은 아님 (지연 시간 약 1초).
- 배치 단위로 상태를 저장하고, 장애 시 체크포인트에서 재시작.
- 대표적으로 Spark Streaming이 사용.
- 단점
- 실시간성이 떨어지고, 체크포인트 접근만으로는 외부 시스템(DB, 브로커 등)에 중복된 출력이 발생할 수 있음.
- 즉, 마이크로 배치 단위 내에서는 “정확히 한 번” 보장이 어렵다.
원자적 커밋 재검토
- 장애 시에도 “모든 출력을 한 번만 발생”시키려면
- 스트림 처리기와 외부 시스템 간의 원자적 커밋(atomic commit) 이 필요
- 하지만 스트림 프레임워크는 여러 노드와 메시지 시스템 간 동기화가 어려워
- 2PC는 현실적으로 비효율적
- 대신, 내부 트랜잭션처럼 동작하는 상태 관리 기반 커밋 방식이 사용
멱등성
- 정확히 한 번 시맨틱스를 달성하기 위한 실용적 접근법.
- 같은 연산이 여러 번 수행되더라도 결과가 동일해야 한다.
- 외부 시스템(예: Kafka, DB)에 쓰기 시 메시지 오프셋이나 마지막 처리 상태를
함께 기록하여 중복 실행 시 동일 결과를 유지하도록 만든다. - Trident (Storm 기반 프레임워크) 등은 이러한 멱등성을 전제로 작업 순서를 보장하며
“정확히 한 번 처리”를 실질적으로 구현한다.
실패 후 상태 재구축
- 스트림 처리에서는 조인, 윈도우, 집계 등 상태를 가진 연산이 많기 때문에 장애 시 상태 복구가 매우 중요
- 복구 방식
- 원본 데이터 재질의
- 모든 입력 이벤트를 재처리하여 동일한 결과 재생성
- 느리지만 단순하고 확실함
- 상태 스냅샷 복원 (Checkpoint Restore)
- 주기적으로 상태를 저장소(HDFS, Kafka 등)에 백업
- 장애 발생 시 해당 시점의 스냅샷을 불러와 빠르게 복구
- 원본 데이터 재질의
- 일부 DB(예: VoltDB)는 노드 간 상태 복제를 통해 장애 시 즉시 복구한다.
- 상태 복제가 불필요한 경우도 있음
- 예: 작은 윈도우라면 입력 스트림을 재처리해도 충분히 빠르게 복구 가능.
트레이드 오프
- 복구 방식 선택은 인프라 성능 특성에 달려 있다.
- 디스크 접근이 느리고 네트워크가 빠른 시스템
- 혹은 그 반대의 시스템 등
- 따라서 “로컬 상태 vs 원격 상태” 중 어떤 쪽을 더 자주 백업할지,
혹은 실시간 복제를 유지할지 등의 트레이드오프 설계가 필요함.
'Book > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| 12. 데이터 시스템의 미래 (0) | 2025.11.10 |
|---|---|
| 10장. 일괄 처리(Batch Processing) (0) | 2025.10.26 |
| Part3. 파생 데이터 (Derived Data) (0) | 2025.10.26 |
| 9장. 일관성과 합의 (Consistency and Consensus) (0) | 2025.10.17 |
| 8장. 분산 시스템의 골칫거리(The Trouble with Distributed Systems) (0) | 2025.10.13 |