❐ 0. Description
이번장 에서는..
- 내결함성을 지닌 분산 시스템을 구축하는데 쓰이는 알고리즘과 프로토콜의 몇 가지 예를 얘기한다.
- 그리고 8장에서 설명한 모든 문제가 발생할 수 있다고 가정한다.
- 시간은 최선을 다하더라도 근사치 밖에 쓸 수 없다.
- 노드는 멈출 수 있고, 언제라도 죽을 수 있다.
내결함성을 지닌 시스템을 구축하는 가장 좋은 방법은?
- 유용한 보장을 해주는 범용 추상화를 찾아 이를 구현하고 애플리케이션에서 이 보장에 의존하는 것.
- 그니깐 모든 애플리케이션에서 각자 장애 복구 로직을 구현하는 건 비효율 적임
대신 신뢰성 있는 공통 추상화 계층을 만들어서, 그 위에 애플리케이션을 올리면
각 앱은 그 보장(트랜잭션, exactly-once)에 의존해 더 안전하게 동작할 수 있음.
합의 (Consensus)
- 분산 시스템에서 가장 중요한 추상화 중 하나
- 어떤 것을 할 수 있고 어떤 것을 할 수 없는지에 대한 범위를 이해해야 함.
❐ 1. 일관성 보장 (Consistency Guarantees)
복제 데이터베이스
- 대부분 최소한 최종적 일관성을 제공
- 쓰기를 멈추고 불특정 시간 동안 기다리면 결국 모든 읽기 요청이 같은 값을 반환(수렴)
- 하지만 이것은 매우 약한 보장(weak guarantee)
- 왜냐면 언제 복제본이 수렴될지에 대한 정보가 하나도 없기 때문
- 이러한 최종적 일관성의 엣지 케이스는 시스템에 결함이 있거나 동시성이 높을 때만 드러남.
강한 일관성 모델
- 앞으로 데이터 시스템이 제공할 수 있는 더 강한 일관성 모델에 대해서 살펴 볼 예정
- 선형성(linearlizability)
- 이벤트 순서화 문제 (인과성과 전체 순서화와 관련된 문제 검토)
- 분산 트랜잭션을 원자적으로 커밋하는 방법
- 강한 보장을 제공하는 시스템은
- 성능이 나쁘거나
- 약한 보장이 제공하는 시스템보다 내결함성이 약할 수도
❐ 2. 선형성 (Linearizability)
아이디어
- 데이터 복사본이 하나만 있는 것처럼 보여주자!
- 읽힌 값이 최근에 갱신된 값임을 보장해줌 ➔ 최신성 보장(recency guarantee)
- 단점은 모든 복제본에 값이 write 될 때 까지 기다여야 하기 때문에 느림
선형성 위반 예시
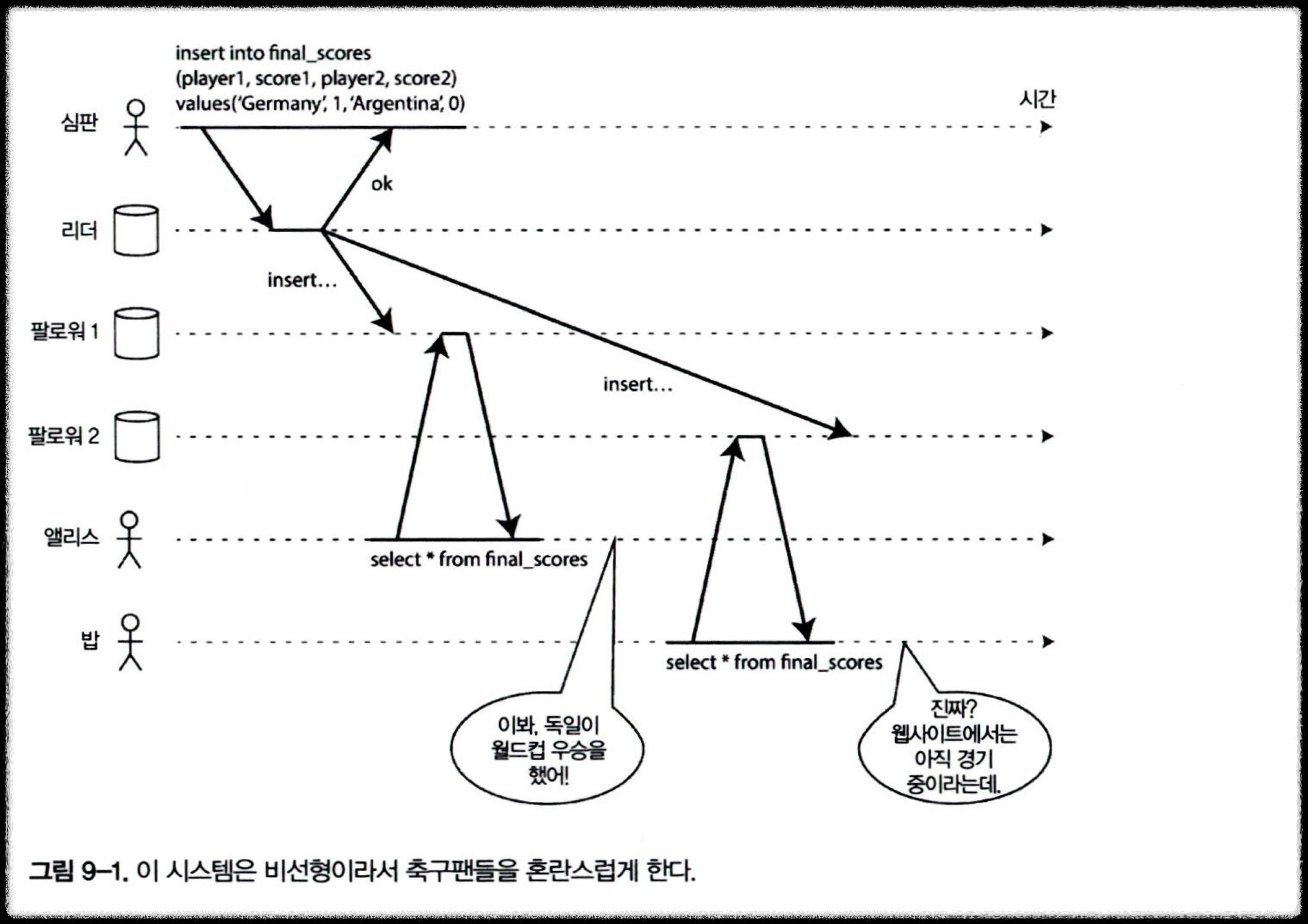
- 복제 지연으로 인해 밥은 앨리스보다 우승자 확인을 늦게하는 상황
- 밥의 질의가 오래된 결과를 반환했다는 사실이 선형성 위반
🌀 2-1. 시스템에 선형성을 부여하는 것은 무엇인가?(What Makes a System Linearizable?)
➔ "복사본이 하나 뿐인 것처럼 보이게 하자"를 이해하기 위해 예제를 살펴보자.
동시에 같은 키(x)를 읽고 쓰는 예시

- 읽기와 쓰기 요청이 동시에 실행되면 과거의 값을 반환할 수도, 새로운 값을 반환할 수도 있음.
- 결과적으로 A,B는 서로 다른 값을 받을 수도 있다.
- 즉, "데이터의 단일 복사본"을 모방하는 시스템에 기대하는 바가 아님!

- 선형 시스템에서는 값이 원자적으로 바뀌는 시점이 있어야 한다고 가정함.
- 예시의 경우에는, A가 x를 1로 읽었으면 B도 1로 읽어야 함.

- 두 번째 타이밍 다이어그램을 개선한 버전. (원자적으로 영향을 주는 개별 연산을 시각화)
- 선형성의 요구사항은 연산 표시를 모은 선들이 항상 시간순으로 진행돼야 함.
- 참고로 위 예시에서 클라이언트B의 마지막 읽기는 선형적이지 않음.
- 이 연산은 x를 2에서 4로 갱신하는 C의 cas쓰기와 동시적
- 다른 요청이 없으면 2가 맞는데 A가 읽기를 했고, 그 결과가 4
- 그렇다면 B도 4를 읽어야 함.
선형성 vs 직렬성
- 직렬성
- 모든 트랜잭션이 여러 객체를 읽고 쓸 수 있는 상황에서의 트랜잭션의 격릴 속성
- 트랜잭션이 어떤 순서에 따라 실행되는 것 처럼 동작하도록 보장해줌.
- 이때 순서가 트랜잭션이 실제로 실행되는 순서와 달라도 상관이 없음.
- ex. 직렬성 스냅숏 격리 ➔ 미리 떠놓은 스냅샷을 읽기 때문에 비선형적
- 선형성
- 레지스터(개별 객체)에 실행되는 읽기와 쓰기에 대한 최신성 보장
- 선형성 연산은 트랜잭션으로 묶지 않음 ➔ "write skew" 같은 문제를 막지 못함.
- ex. 2PL, 실제적인 직렬 실행을 기반으로 한 직렬성 구현
선형성 + 직렬성
- 선형성과 직렬성의 조합을 '엄격한 직렬성' 또는 '강한 단일 복사본 직렬성' 이라고 함.
🌀2-2. 선형에 기대기 (Relying on Linearizability)
➔ 어떤 환경에서 선형성이 유용한지 알아보자.
잠금과 리더 선출
- 단일 리더 복제 시스템은 스플릿 브레인을 방지하기 위해 하나의 리더만 선출해야 한다.
- 이를 보장하기 위해서 잠금을 사용하는 것인데, 이 잠금의 구현은 무조건 선형적이여야 함.
- 분산 잠금과 리더 선출을 구현하기 위해 코디네이션 서비스가 사용되는데
이들은 합의 알고리즘을 사용해 선형성 연산을 내결함성이 있는 방식으로 구현함.
제약 조건과 유일성 보장
- 데이터를 기록할 때 유일성 조건을 강제하고 싶다면 선형성이 필요함.
- 예를 들면 서비스 가입할 때, 닉네임이 점유되어 있지 않다면 사용 가능
채널 간 타이밍 의존성

- 파일 저장 서비스가 비선형적이라면? (선형적이라면 위 플로우는 문제 없음.)
- 현재 '이미지 크기 변경 모듈'은 두개의 채널과 통신함. ➔ 메시지 큐 & 파일 저장소
- 이때, 메시지 큐가 저장소 내부의 복제보다 빠를 수도 있음.
- 모듈이 과거 버전 이미지를 처리하게 될 수도 있음.
- 이렇게 되면, 원래 크기의 이미지와 변경된 이미지가 영구적으로 불일치하게 됨.
- 즉, 선형성의 최신성 보장이 없으면 이 두 채널 사이에 경쟁 조건이 발생할 수 있음.
더보기
예상 시나리오
- 사용자가 "ABC.png" 업로드. 그리고 큐에 메시지 "ABC-1" 전달
- 모종의 이유로 큐에서 딜레이 발생
- 그 사이에 사용자가 이미지로 교체함(이때 이미지 명 같음). 그리고 큐에 메시지 "ABC-2" 전달
- 큐 내부 사정이나 네트워크 지연 때문에 "ABC-2"를 먼저 모듈에 전달.
- 모듈에서 "ABC-2"의 정보를 바탕으로 리사이즈
- 그리고 큐에서 "ABC-1"를 모듈에 전달.
- 과거의 정보를 바탕으로 리사이즈된 이미지가 최종적으로 저장됨.
더보기
해결 방법
- 이벤트 순서 제어
- 메세지에 타임스탬프 또는 버전 정보를 추가해서 가장 최신 이벤트만 처리하도록 하기
- payload 정보 변경 + 재시도 메커니즘(retry, outbox 등등)
- payload에 메시지의 UUID를 넘기고, UUID를 기반으로 리사이즈하기
- 만약 DB에 저장되기 전에 메시지가 소비 될 경우를 대비해서 재시도 메커니즘 구현
🌀 2-3. 선형성 시스템 구현하기
➔ 정말 심플하게 진짜 복사본을 하나만 사용하기. 그러나 이 방법으로 결함을 견뎌낼 수 없다.
5장에서 봤던 내용을 선형적으로 만들 수 있을까?
- 단일 리더 복제 (선형적이 될 가능성이 있음)
- 합의 알고리즘 (선형적)
- 다중 리더 복제 (비선형적)
- 리더 없는 복제 (아마도 비선형적)
- '일 기준 시계'를 기반으로 LWW 충돌 해서 방법은 거의 확실히 비선형적
- 시계 타임스탬ㅁ프는 clock skew 때문에 이벤트의 실제 순서와 일치함을 보장할 수 없기 때문
선형성과 정족수

| n | 3 |
| w | 3 |
| r | 2 |
| w + r > n | 5 > 3 (true) |
- 엄격한 정족수를 사용하지만 비선형적인 실행 케이스
- A의 요청이 완료된 후, B가 요청함.
- 선형적이라면 B는 1을 읽어야 하는데, 0을 읽음.
- 결과적으로 비선형적
- 다이나모 스타일 정족수를 선형적으로 만드는게 가능함(성능은 당연히 저하됨)
- 읽기 복구를 동기식으로 처리해서 가능하게 함.
🌀 2-4. 선형성의 비용
단일 리더 설정은 비선형적
- 단일 리더 설정에서 데이터센터 사이의 네트워크가 끊기면 팔로워 데이터센터로 접속한
클라이언트들은 리더로 연결할 수 없으므로 데이터베이스에 아무것도 쓸 수 없고,
선형성 읽기도 전혀 할 수 없음. - 팔로워로부터 읽을 수는 있지만 데이터가 최신이 아닐수 있음.(비선형적)
CAP(Consistency / Availability / Partition tolerance) 정리
- 일관성, 가용성, 분할 허용성 사이의 trade-off를 설명하는 정리
- 원래는 데이터베이스에서 trade-off에 대한 논의를 시작하려는 목적
- 정확한 정의 없이 경험 법칙으로 제안됐음.
- 공식적으로 정의된 CAP 정리는 매우 범위가 좁음.
➔ 오직 하나의 일관성 모델과 한 종류의 결함만 고려함. - 결론 : 역사적 영향력은 있는데 시스템을 설계할 때는 실용적 가치 없음.
도움이 안되는 CAP 정리
- CAP은 때때로 '일관성', '가용성', '분할 허용성' 중 2개를 고르라는 것으로 표현됨.
- 근데 이런 식으로 생각하면 오해의 소지가 있음.
- 왜? 네트워크가 올바르게 동작할 때는 시스템이 일관성(선형성)과 가용성 모두를 제공하기 때문임.
➔ CAP의 올바른 정의 : "네트워크 분단(Partition)이 생겼을 때" 일관성과 가용성 중 하나를 선택하라
선형성과 네트워크 지연
- 선형성은 (네트워크가 정상이든, 아니든) 항상 느리다.
- 따라서 선형성을 보장하면, 성능이 떨어진다.
❐ 3. 순서화 보장 (Ordering Guarantees)
🌀 3-1. 순서화와 인과성
순서화는 인과성을 보존하는데 도움을 준다.
- 인과성은 이벤트에 순서를 부과한다.
- 결과가 나타나기 전에 원인이 발생한다.
- 메시지를 받기 전에 메시지를 보낸다.
- 답변하기 전에 질문한다.
- 시스템이 인과성에 부과된 순서를 지키면
➔ 그 시스템은 인과적으로 일관적(causally consistent)이라고 한다.- 스냅숏 격리가 인과적 일관성을 제공하는 예시
- 어떤 데이터를 읽었어. 그럼 이 데이터보다 인과적으로 먼저 발생한 데이터도 볼 수 있어야 함.
수학적 집합은 부분적으로 순서가 정해짐(partially ordererd)
- {a, b, c} / {a, b} / {b, c} ➔ 이런 경우라면 포함관계를 설명할 수 있기 때문에 비교할 수 있음.
- {a, b} / {b, c} ➔ 이 경우에 각 요소는 어떤 집합과의 포함관계를 설명할 수 없기 때문에 비교할 수 없음.
인과적 순서가 전체 순서는 아니다. (선형성 ≠ 인과성)
- 선형성
- 연산의 전체 순서를 정할 수 있다.
- 복사본이 하나만 있는 것처럼 동작하고 모든 연산이 원자적이면
어떤 두 연산에 대해 항상 둘 중 하나가 먼저 실행됐다고 할 수 있다는 뜻 - 선형성 데이터스토어에는 동시적 연산이 없다.
- 하나의 타임라인이 있고, 모든 연산은 그 타임라인을 따라서 전체 순서가 정해져야 한다.
- 인과성
- 동시에 실행되면 비교할 수가 없다.
- 인과성이 전체 순서가 아니라 부분 순서를 정의한다는 뜻
- 동시성은 타임라인이 갈라졌다가 다시 합쳐지는 것을 의미한다.
- 이 경우 다른 branch에 있는 연산은 비교 불가(즉, 동시적)하다.
선형성은 인과적 일관성보다 강하다.
- 선형성은 인과성을 내포한다.
- = 어떤 시스템이든지 선형적이라면 인과성도 올바르게 유지한다.
- 근데 앞서 말했듯이 시스템을 선형적으로 만들면, 성능과 가용성이 떨어진다.
- 하지만, 선형성이 인과성을 보존하는 유일한 방법은 아니다.
- 선형성이 필요해 보이는 경우, 진짜 필요한건 일관적 일관성
인과적 의존성 담기 (Capturing causal dependencies)
- 인과성을 유지하기 위해서는 어떤 연산이 다른 연산보다 먼저 실행 됐는지 알아야 한다.
- 이를 알기 위해서 단일 키 뿐만 아니라 전체 데이터베이스에 걸친 인과적 의존성을 추적해야 한다.
- 인과적 순서를 결정하기 위해 데이터베이스는 애플리케이션이 데이터의 어떤 버전을 읽었는지 알아야 한다.
🌀 3-2. 일련번호 순서화(Sequence Number Ordering)
일련번호나 타임스탬프를 써서 이벤트 순서를 정하기
- 모든 인과적 의존성을 실제로 추적하는 것은 오버헤드가 큼.
- 더 좋은 방법으로는 '일련번호' 나 '타임스탬프' 를 써서 이벤트 순서를 정하는 것
- 앞에서 학습했듯, 타임스탬프는 논리적 시계에서 얻어도 됨.
- 논리적 시계는 연산을 식별하는 시퀀스를 생성하는 알고리즘임.
- 보통 모든 연산마다 증가하는 카운터를 사용함.
일련번호 or 타임스탬프
- 크기가 작고, 전체 순서를 제공함.
- 즉, 모든 연산은 고유 시퀀스를 갖고 항상 두 개의 시퀀스를 비교하면 됨.
- 인과성에 일관적인 전체 순서대로 일련번호를 생성할 수 있음.
- 연산 A가 B보다 인과적으로 먼저 실행됐다면, A는 전체 순서에서도 B보다 먼저임.
- 근데 연산 C, D가 동시에 일어났다면?
- 동시적인 연산은 서로 인과관계가 없기 때문에 둘 중 뭐가 먼저와도 노상관
- A > B > C > D or A > B > D > C
- 순서화를 더 부과한다? ➔ 인과성이 없는 연산도 순서를 매겨 버림.
- 결과적으로 이 방식은 인과 관계를 잘 반영해서, 전체 순서를 잘 만들어줌. (A,B)
- 근데 동시적에 발생한 연산의 경우에도 강제로 순서를 매겨버림. (C, D)
더보기
UUID로 만든 전체 순서의 문제점.
- 랜덤 UUID는 서로 비교할 수 있기 때문에, 전체 순서를 만들 수 있음.
- 실제로 A가 먼저 발생하고 B가 발생한 상황에서 UUID를 비교했는데,
B가 먼저 발생한 상황이라고 결정하는 문제가 있을 수 있음. - 결과적으로 UUID를 사용한 전체 순서는 인과성이 깨지게 됨
단일 리더 환경이 아닌 경우 일련번호를 생성하는 방법
- 각 노드가 자신만의 독립적인 일련번호 집합을 생성
- 예를 들어 노드 두 대가 있으면 한 노드는 홀수만, 다른 한 노드는 짝수만
- 각 연산에 '일 기준 시계'에서 얻은 타임스탬프를 사용하기
- 이 타임스탬프가 순차적이진 않지만, 해상도가 높다면(자리수가 크다면) 충분함
- 일련 번호 블록을 미리 할당
- A노드는 1 ~ 1000, B노드는 1001 ~ 2000
➔ 위 세가지는 확장성이 좋지만, 생성한 일련번호가 인과성에 일관적이지 않게 된다.
위 세가지 방법의 문제점
- 각 노드는 초당 연산수가 다를 수 있음.
- 짝수용 카운터가 홀수용 카운터보다 뒤처지거나 하는 상황이 발생할 수 있음.
- 즉, 홀수 연산과 짝수 연산 중 어떤 것이 인과적으로 먼저 실행됐는지 알 수 없음.
- 물리적 시계에서 얻은 타임스탬프는 시계 스큐에 종속적이러서 인과성에 일관적이지 않을 수 있음.

- 인과적으로 나중에 실행된 연산(B)이 실제로 더 낮은 타임스탬프를 배정 받음.
- 1003 번이 199번보다 먼저 실행되는 상황이 발생할 수 있음.
램포트 타임 스탬프

- 핵심 개념
- 인과 관계를 만족시키는 논리적 시계(Logical Clock)
- 실제 물리적 시간이 아니라, “어떤 이벤트가 다른 이벤트보다 앞섰다”는 관계만을 보장하는 시계
- 메커니즘
- 각 노드는 고유 식별자를 갖고, 각 노드는 처리한 연산 개수를 카운터로 유지
- 램포트 타임스탬프는 그냥 [카운터, 노드ID] 의 쌍
- 때로 같은 카운터 값이 같을 수 있지만, 타임스탬프에 노드 ID를 포함시켜서 유일성을 보장
- 핵심 아이디어
- 모든 노드와 모든 클라가 지금까지 본 카운터 값 중 최대값을 추적하고 모든 요청에 그 값을 포함시킨다.
- 노드가 자신의 카운터 값보다 큰 카운터를 가진 요청/응답을 받으면 바로 그 값으로 최대값을 증가
- 이 방법은 램포트 타임스탬프로부터 얻은 순서가 인과성에 일관적이도록 보장해줌.
- 버전 벡터와의 차이점
- 버전 벡터는 두 연산이 동시적인지 인과적인지 구분할 수 있음. (부분 순서만 표현)
- 램포트 타임스탬프는 항상 전체 순서화를 강제함.
타임스탬프 순서화로는 충분하지 않다.
➔ 유일한 사용자 계정을 생성하는 시나리오
- 람포트 타임스탬프로 해결할 수 있을 것 같지만 그렇지 않음.
- 사용자 생성 요청을 당장 결정해야 하는 경우를 생각해봐야 함.
- 노드A가 `username = gilbert`요청을 받음.
- 이 요청을 지금 바로 처리해도 되는지 여부를 판단해야 함.
- 이 시점에 노드A는 다른 노드들이 무슨 일을 하고 있는지 모름.
- 결국 “지금 시점”에서는 안전하게 결정할 근거가 없음.
- 즉, 모든 노드의 정보(연산)를 받아야만 전체 순서를 알 수 있는 거임.
- 램포트 타임스탬프가 딱 이런 케이스임.
🌀 3-3. 전체 브로드 캐스트
전체 순서 브로드 캐스트(= 원자적 브로드캐스트)
- 단일 리더 복제는 한 노드를 리더로 선택하고 리더의 단일 CPU 코어에서 모든 연사을
차례대로 배열함으로써 연산의 전체 순서를 정함 - 여기서 어려운 문제는 처리량이 단일 리더가 처리할 수 있는 수준을 넘었을 때임.
- 분산 시스템 분야에서는 위 문제를 이 방법으로 해결하는 것으로 알려져 있음.
- 전체 순서 브로드캐스트(total order broadcast) = 원자적 브로드캐스트(atomic broadcast)
전체 순서 브로드캐스트란?
- 분산 시스템에서 모든 노드가 같은 순서로 같은 메시지를 받도록 보장하는 통신 방식
- 두 가지 안전성 속성을 항상 만족해야 한다.
- 신뢰성 있는 전달 (Reliable delivery)
- 전체 순서가 정해진 전달 (Totally ordered delivery)
- 물론 네트워크가 끊긴 경우에는 메시지 전달을 못하지만, 복구되면 원래대로 동작해야 한다.
- Zookeeper나 etcd 같은 합의 서비스는 전체 순서 브로드캐스트를 실제로 구현한다.
전체 순서 브로드캐스트 사용하기
- 데이터베이스 복제
- 상태 기계 복제(state machine replication)
- 모든 메시지가 데이터베이스에 쓰기를 나타내고 모든 복제 서버가 같은 쓰기 연산을
같은 순서로 처리하면 복제 서버들은 서로 일관성 있는 상태를 유지하는 원리
- 모든 메시지가 데이터베이스에 쓰기를 나타내고 모든 복제 서버가 같은 쓰기 연산을
- 상태 기계 복제(state machine replication)
- 직렬성 트랜잭션 구현
- 모든 복제 서버가 쓰기 연산을 같은 순서로 처리하면, 서로 일관성 있는 상태를 유지
- 상태 기계 복제(state machine replication)
- 로그를 만드는 방법 중 하나
- 메시지 전달은 모든 노드의 로그에 그 메시지를 추가하는 것과 비슷하다.
- 이렇게 하면 모든 노드가 같은 순서로 로그를 쌓기 때문에 동일한 메시지를 볼 수 있음.
- 펜싱토큰을 제공하는 서비스 구현하는데 유용
- 잠금을 획득하는 모든 요청은 메시지로 로그에 추가
- 모든 메시지들은 로그에 나타난 순서대로 일련번호가 붙음.
- 그러면 일련번호는 단조 증가하므로 펜싱 토큰의 역할을 수행할 수 있음.
TOB 특징
- 메시지가 전달되는 시점에 그 순서가 고정됨.
- 중간에 소급적용이 불가능 (즉, 끼워 넣기 X)
- 이러한 이유로 타임스탬프 순서화보다 강하다고 함.
TOB를 사용해 선형성 저장소 구현하기
- 선형성과 TOB가 같다고 할 순 없지만, 어느정도 링크되어 있음.
- 전체 순서 브로드캐스트
- 비동기
- 고정된 순서는 보장하지만, 언제 전달될지는 보장되지 않음.
- 선형성
- 최신성 보장
- 전체 순서 브로드캐스트
- `TOB(추가 전용 로그로 사용) + CAS 연산`
- 클라이언트 A(나), B가 동시에 "gilbert" 생성 시도.
- 로그 순서는 TOB가 [Create(A), Create(B)]로 확정. ➔ 모든 노드가 동일하게 가지고 있게됨.
- "gilbert"라는 이름에 대해 처음 등장한 메시지가
- 나의 메시지라면? 내가 닉 먹는거임
- 내 메시지가 아니라면? 나의 요청은 abort
- 만약 동일한 메시지가 처리된다면?
- 멱등성 보장을 통해 동일한 결과를 반환
- 근데 이 방법은 선형성 읽기는 보장하지 않음.
- 로그로부터 비동기로 갱신되는 저장소를 읽으면 오래된 값이 읽힐 수 있음.
- 읽기를 선형적으로 만들기 위한 몇 가지 선택지가 있음.
- 로그 순서에 따라 읽기
- 로그의 최신 위치를 동기화한 후 읽기
- 최신 복제본에서만 읽기
선형성 저장소를 사용해 TOB 구현하기
➔ 선형성이 보장되면 TOB 구현할 수 있다.
- 구현 아이디어
- 전역 카운터
- 선형성을 보장하는 저장소에 정수를 저장한다.
- 이 정수는 전역적으로 하나뿐인 “메시지 번호” 역할을 한다.
- 원자적 `increment-and-get` 연산을 지원한다고 가정한다.
- 메시지를 보낼 때
- 브로드캐스트하고 싶은 메시지를 만들 때, 먼저 increment-and-get을 실행해서
➔ 그 결과값을 메시지의 “일련번호(sequence number)” 로 붙인다.
» increment-and-get() 연산이 전역에서 단 하나의 순서로 실행됨 - 모든 노드로 전송
- 메시지와 함께 부여된 일련번호를 다른 노드들에게 보낸다.
- 모든 노드가 동일한 순서로 메시지를 전달받게 된다.
- 메시지가 유실되면 재전송 가능.(일련번호가 있으므로 중복 판별 가능)
- 브로드캐스트하고 싶은 메시지를 만들 때, 먼저 increment-and-get을 실행해서
- 전역 카운터
- 램포트 타임스탬프와의 차이점
- 선형성 레지스터를 증가시켜 순열을 형성함.
- 즉, 순열(sequence)이 실제 순서와 100프로 동일함.
선형성, TOB == 합의
- 단일 노드에서 레지스터를 구현하는건 간단하지 않은 문제임.
- 노드가 죽거나, 네트워크가 끊기는 경우엔?
- 즉, "전역적으로 레지스터”를 만들려면 노드 간 의견이 완전히 일치해야 함.
➔ 이건 바로 합의(Consensus) 문제의 본질
- 선형성과 TOB가 합의 문제로 귀결되는 이유
- 결국엔 모든 노드가 다음에 어떤 값이 되어야 하는지 동의해야 하기 때문
❐ 4. 분산 트랜잭션 합의
합의
- 분산 컴퓨팅에서 가장 중요하고 근본적인 문제 중 하나.
- 쉽게 말하면(Informally), 합의의 목적은 단지 여러 노드들이 뭔가에 동의하게 만드는 것임
- 노드가 동의하는 것이 중요한 케이스
- 리더 선출
- 원자적 커밋
- 노드가 동의하는 것이 중요한 케이스
합의 불가능성
- FLP 정리
- 어떤 노드가 죽을 위험이 있다면 항상 합의에 이를 수 있는 알고리즘은 없다를 증명한 것
- 아주 제한적인 조건(이상적인 가정) 아래에서만 “불가능”을 증명함.
- 분산 시스템에서는 노드가 죽을 수 있다고 가정하기에, 신뢰성 있는 합의는 불가능함.
- 하지만 현실 세계에서는 가능함. (타임아웃, 노드가 죽었음을 판단하는 다른 방법 등.. 으로)
🌀 4-1. 원자적 커밋관 2단계 커밋
단일 노드에서 분산 원자적 커밋으로 (From single-node to distributed atomic commit)
- 단일 노드에서 트랜잭션 커밋은
- 데이터가 디스크에 지속성 있게 쓰여지는 순서에 결정적으로 의존한다.
- 만약 트랜잭션에 여러 노드가 관련한다면? (ex. 다중 객체 트랜잭션, 용어 파티셔닝된 보조 색인)
- 이 경우, 원자성을 보장할 수 없기 때문에 각 노드에서 독립적으로 트랜잭션을 커밋하는 것은 충분하지 않음.
- 트랜잭션 커밋을 되돌릴 수 없음.
- 물론 보상 트랜잭션 (compensating transaction)으로 비슷해 보이게 할 순 있는데
데이터베이스의 관점에서 이는 엄연히 분리된 트랜잭션.
➔ 트랜잭션 사이에 걸친 정확성 요구사항은 application의 몫
- 물론 보상 트랜잭션 (compensating transaction)으로 비슷해 보이게 할 순 있는데
2단계 커밋 소개 (Introduction to two-phase commit)
- 여러 노드에 걸친 원자적 트랜잭션 커밋을 달성하는 것을 보장하는 알고리즘
- 단일 노드 트랜잭션에서는 보통 존재하지 않는, 코디네이터(coordinator)를 사용함.
- 코디네이터는 주로 애플리케이션 프로세스 내에서 라이브러리로 구현됨.
- 분리된 프로세스나 서비스가 될 수도 있음.
2단계 커밋 메커니즘
➔ 2PC의 commit/abort 과정은 두 단계로 나뉨 (그래서 이름이 이럼)

- 평소처럼 애플리케이션이 여러 DB 노드에서 데이터를 읽고 쓰면서 시작
- 여러 DB노드를 참여자(participant)라고 부름
- 애플리케이션이 커밋할 준비가 되면 코디네이터가 1단계를 시작함.
- 각 노드에 준비 요청을 보내서 커밋할 수 있는지 물어봄
- 그 후 코디네이터는 참여자들의 응답을 추적함.
- 참여자 중,
- 모두 "Yes"로 응답하면 코디네이터는 2단계에서 commit 요청 & commit됨.
- 하나라도 "No"로 응답하면 abort 요청을 보냄
약속에 관한 시스템 (A system of promises)
- 애플리케이션 분산 트랜잭션 희망
- 애플리케이션은 코디네잍어에게 트랜잭션 ID를 요청한다.
- ID는 전역으로 유일함.
- 애플리케이션은 각 참여자(DB 노드)에서 단일 노드 트랜잭션 시작
- 단일 노드 트랜잭션에 전역적으로 유일한 트랜잭션 ID를 붙임
➔ 이렇게 하면 문제가 생겨도 코디네이터나 참여자중 누군가가 abort 시킬 수 있음.
- 단일 노드 트랜잭션에 전역적으로 유일한 트랜잭션 ID를 붙임
- 애플리케이션 커밋 준비 상태
- 코디네이터는 모든 참여자에게 전역 트랜잭션 ID로 태깅된 준비 요청을 보냄.
- 보낸 요청 중 하나라도 실패 or 타임아웃 터지면 그 트랜잭션 ID로 abort 요청 보냄
- 참여자가 준비 요청 받으면 모든 상황에서 트랜잭션을 커밋할 수 있는지 확인
- 이때 참여자는 제약 조건 위반이나 충돌이 없는지도 미리 검사해야 한다.
- 코디네이터의 최종 결정
- 모든 준비 요청에 대해 응답을 받았을 때 커밋할 것인지 abort할 것인지 결정
- 코디네이터는 추후 죽는 경우에 어떻게 결정했는지 알 수 있도록 그 결정을 디스크에 있는
트랜잭션 로그에 기록해야 함. 이를 커밋 포인트라고 함.
- 모든 참여자에게 결과(commit or abort) 요청 전송
- 만약 요청 전송에 문제가 생기면, 성공할 때 까지 무한 재시도
2PC가 원자성을 보장하는 근거
- 참여자가 "Yes"에 투표할 때, 나중에 무조건 커밋할 수 있음을 약속함.
- 코디네이터도 한 번 결정하면 그 결정을 변경할 수 없음(위에서 본 무한 재시도)
코디네이터 장애
- 준비 요청을 보내기 전에는 트랜잭션을 abort 할 수 있음.
- 참여자가 준비 요청을 받고 "Yes"에 투표했다면 트랜잭션을 일방적으로 abort 할 수 없음.
- 일단 코디네이터로부터 커밋/어보트 여부를 회신 받을 때까지 대기 해야함.
- 이런 상태에서 참여자의 트랜잭션을 의심스럽다(in doubt), 불확실하다(uncertain)고 함.
- 코디네이터에 장애가 생기면 복구되기를 기다려야 함
- 코디네이터는 2PC를 완료할 수 있는 유일한 방법이기 때문.
- 코디네이터가 복구되면 트랜잭션 로그를 읽어서 의심스러운 트랜잭션의 상태를 결정
3단계 커밋
- 2PC는 코디네이터가 복구하시를 기다리는 경우가 있어, 블로킹 원자적 커밋 프로토콜이라고 불림.
- 이론상으로 논블로킹하게 만들 수 있긴 함. 근데 간단하진 않음.
- 3PC
- 3PC는 지연에 제한이 있는 네트워크와 응답 시간에 제한이 있는 노드를 가정함.
- 기약 없는 네트워크 지연 or 프로세스 중단이 있는 경우, 3PC는 원자성 보장 못함.
- 일반적으로 논블로킹 원자적 커밋은
- 완벽한 장애 감지기 (perfect failure detector) 메커니즘이 필요
- 암튼, 이런 이유로 2PC가 계속 쓰임
🌀 4-2. 현실의 분산 트랜잭션
엇갈린 평판
- 긍정 : 달성하기 어려운 중요한 안전성 보장을 제공하는 것으로 봄
- 부정 : 운영상의 문제를 일으키고 성능을 떨어뜨린다고 봄
- ex. MySQL의 분산 트랜잭션은 단일 노드 트랜잭션 보다 10배 이상 느림
➔ 디스크 강제 쓰기 & 네트워크 왕복 시간
- ex. MySQL의 분산 트랜잭션은 단일 노드 트랜잭션 보다 10배 이상 느림
두 가지 종류의 분산 트랜잭션
- 데이터베이스 내부 분산 트랜잭션
- 하나의 분산 데이터베이스 시스템 내부에서 발생하는 트랜잭션
- 같은 DB 소프트웨어 안에서 여러 노드가 하나의 트랜잭션에 참여하는 형태
- ex. MySQL NDB Cluster, VoltDB, CockroachDB
- 이종 분산 트랜잭션 (Heterogeneous Distributed Transaction)
- 서로 다른 기술이 섞인 트랜잭션이에요.
- 트랜잭션에 참여하는 시스템이 DB만 있는 게 아니라 메시지 브로커, 다른 벤더의 DB일 수도 있음.
- ex. Oracle DB + Kafka 메시지 큐 + MySQL DB
정확히 한 번 메시지 처리 (Exactly-once message processing)
- 큐에서 나온 메시지는 그 메시지를 처리하는 DB 트랜잭션이 커밋에 성공했을 때만 처리된 것 간주할 수 있음.
- (메시지 확인 + 데이터베이스 쓰기)를 단일 트랜잭션에서 원자적 단위로 묶으면,
중간에 장애가 나도 재시도를 통해 effectively-once processing 보장할 수 있음. - 그러나 이런 분산 트랜잭션은,
- 트랜잭션에 영향을 받는 모든 시스템이 동일한 원자적 커밋 프로토콜을 사용할 수 있을 때만 가능
XA(eXtended Architecture) 트랜잭션
- X/Open XA는 이종 기술에 걸친 2PC을 구현하는 표준이다.
- XA는 postgresql, mysql, db2, sql서버, 오라클을 포함한 여러 관계정 데이터베이스와
엑티브MQ, 호닛MQ를 포함한 메시지 브로커에서 지원됨. - XA는 네트워크 프로토콜이 아니고 트랜잭션 코디네이터와 연결되는 인터페이스틑 제공하는 API
- XA는 애플리케이션이 네트워크 드라이버나 클라이언트 라이브러리를 사용해
참여자 DB나 메시징 서비스와 통신한다고 가정함. - 코디네이터가 죽었다 깨어나면 XA 콜백을 사용해서 디스크에 저장한 상태를 공유함.
의심스러운(in doubt) 상태에 있는 동안 잠금을 유지하는 문제
- 트랜잭션은 커밋/어보트 될 때까지 잠금을 가지고 있어야 하는데,
2PC를 사용하면 의심스러운 트랜잭션은 상태가 변경되기 전까지 계속 잠금을 잡아야 함.
코디네이터 장애에서 복구하기
- 앞에서는 코디네이터가 부활하면 의심스러운 트랜잭션을 해소한다고 학습했음.
- 그러나 현실에서는 고아+의심 트랜잭션(orphaned in-doubt transactions)이 생길 수 있음.
- 트랜잭션 로그 손실, 소프트웨어 오염 등의 이유로
- 이런 트랜잭션은 영원히 잠금을 유지한테로 남아있게 됨.
- DB 서버 재부팅하면? 그래도 안됨.
- 2PC의 메커니즘은 재시작하더라도 in-doubt 트랜잭션의 잠금을 유지해야 함.
- 그렇지 않으면 원자성을 위반할 위험이 있음.
- 이걸 해결하려면, 관리자가 개입해야 함(수동 작업 필요)
- 여러 XA 구현체는 참여자가 독단적으로 의심서르오누 트랜잭션을 커밋/어보트할지 결정할 수 있는
경험적 결정(heuristic decision)이라고 부르는 대책이 있긴함.- 근데 경험적은 2PC의 약속 체계를 위반하는 거임.
- 아마도 원자성을 깰 수 있다를 완곡하게 표현하는 것.
분산 트랜잭션의 제약
➔ 11장, 12장에서 대안적인 방법 학습할 예정
- 단일 장애점(Single Point of Failure) 문제
- 트랜잭션 코디네이터가 단일 노드에서 실행되면, 장애가 발생 시 전체 시스템이 멈출 수 있음.
- 코디네이터 장애 시 트랜잭션이 잠금 상태로 남거나 다른 애플리케이션 서버까지 영향을 받음.
- 대부분의 코디네이터 구현체는 고가용성(HA) 을 지원하지 않거나 제한적인 복제만 제공함.
- 애플리케이션 서버 비정상 종료 문제
- 트랜잭션 참여자 중 하나라도 비정상 종료되면, 코디네이터가 그 상태를 알 수 없음.
- 재시작 시 트랜잭션의 일관성 복구를 위해 데이터베이스 로그나 별도의 저장소가 필요하지만,
대부분의 애플리케이션 서버는 이에 적합하지 않음.
- 공통 분모(Shared Protocol) 부재
- 서로 다른 데이터베이스/시스템이 함께 XA 트랜잭션을 수행하려면 최소한의 공통 프로토콜이 필요.
- 하지만 각 DB나 시스템이 표준화된 방식(예: SSI)을 따르지 않으면 일관성을 유지하기 어려움.
- XA가 아닌 시스템 간의 제한
- XA를 지원하지 않는 데이터베이스나 내부 DB에서는 분산 트랜잭션이 불가능함.
- 일부 2PC(성공 사례도 있지만, 시스템 일부가 응답하지 않으면 실패함.
- 따라서 장애에 취약하고 복구가 어려움.
🌀 4-3. 내결함성을 지닌 합의
합의 문제
- 합의 문제는 일반적으로 다음과 같은 방식으로 정리해서 설명할 수 있음.
- 하나 이상의 노드가 값을 제안하고 합의 알고리즘이 그 제안들 중 하나를 최종 값으로 결정
- 위 정의에 따르면, 합의는 아래의 속성을 만족해야 함.
- 안전성 속성 (내결함성 상관없으면 이 세개 속성 만족시키는 건 쉬움)
- 균일한 동의 : 어떤 두 노드도 다르게 결정하지 않는다.
- 무결성 : 어떤 노드도 두 번 결정하지 않는다.
- 유효성 : 한 노드가 값v를 결정하면, 어떤 노드에서 제안된 것이다.
- 활성성 속성
- 종료 : 죽지 않는 모든 노드는 결국 어떤 값을 결정한다.
- 안전성 속성 (내결함성 상관없으면 이 세개 속성 만족시키는 건 쉬움)
- (균일한 동의 + 무결성)은 합의의 핵심 아이디어
'종료 속성' 자세히 알아보기
- 종료 속성은
- 내결함성의 아이디어를 형식화(정의)한다.
- 본질적으로 합의 알고리즘은 걍 계속 진행해야 한다고 규정한다.
- 어떤 노드들에 장애가 생겨도, 나머지 멀쩡한 노드들은 결정을 내려야함.
- 죽거나 연결할 수 없는 노드 대수가 절반 미만이라는 가정에 종속적
- 대부분의 합의 구현은 과반수의 노드에 장애가 나거나 심각한 네트워크 문제가 있더라도
- 안정성 속성(동의, 무결성, 유효성)을 항상 만족함.
- 그러므로 서버는 죽더라도, 유효하지 않은 결정을 내려서 합의 시스템을 오염시키진 않음.
대부분의 합의 알고리즘은 비잔틴 결함이 없다고 가정
- 노드가 프로토콜을 올바르게 따르지 않으면 프로토콜의 안전성 속성이 깨지게 됨.
'합의 알고리즘'과 '전체 순서 브로드캐스트(TOB)'
- 널리 알려진 내결함성을 지닌 합의 알고리즘 (유사하지만 같지는 않음)
- 뷰스탬프 복제 (Viewstamped Replication)
- 팍소스(Paxos) ➔ Leaderless
- 멀티 팍소스(Multi-Paxos) ➔ Leader-based
- 라프트(Raft) ➔ Leader-based
- 잽 (Zab)
- 위 알고리즘에서 '형식적 모델'을 직접 사용하진 않고, 값의 순차열을 결정해서 TOB 알고리즘을 만듬
- TOB는 “모든 노드가 같은 순서로 메시지를 받게 하기 위해” 각 메시지 순서마다 합의를 반복해서 실행하는 과정
- 뷰스탬프 복제, 라프트, 잽은 전체 순서 브로드캐스트를 직접 구현함
- 이렇게 하는게 매번 합의를 하는 것보다 효율적이기 때문
단일 리더 복제와 합의
- 합의를 하려면 리더가 필요하고, 리더를 정하려면 합의가 필요 (닭이 먼저냐 달걀이 먼저냐)
에포크 번호 붙이기와 정족수
➔ 지금까지 설명한 합의 프로토콜은 단일 리더를 보장하지 않음.
- 앞서 설명한 프로토콜들은 에포크 번호를 정의하고 각 에포크 내에서는 리더가 유일하다고 보장
- 팍소스 - 투표 번호(ballot number)
- 뷰스탬프 복제 - 뷰 번호(view number)
- 라포트 - 텀 번호(term number)
- 에포크 번호는 전체 순서가 있고 단조 증가함. 따라서 번호가 큰 놈이 리더가 됨.
- 물론, 정족수로부터 투표를 받음.
- 노드들은 총 두 번의 투표를 함. (이 때 투표를 하는 정족수는 겹쳐야 함.)
- 리더 선출하기 위해서
- 리더의 제안에 투표하기 위해서
- 이 투표는 2PC와 비슷해 보이긴 함.
- 정리하자면, 모든 노드가 응답해야 하지만, 합의 알고리즘은 과반수만 응답해도 됨.
합의의 제약
- 합의 시스템은 항상 엄격한 과반수가 동작하기를 요구함.
- 대부분 합의 알고리즘은 투표에 참여하는 노드 집합이 고정돼 있다고 가정
- 이는 클러스터에 노드를 그냥 추가하거나 제거할 수 없다는 뜻
- 합의 알고리즘의 동적 멤버십(dynamic membership) 확장은 클러스터에 있는 노드 집합이
시간이 지남에 따라 바뀌는 것을 허용하지만, 이들은 정적 멤버십 알고리즘보다 이해하기 어려움. - 합의 시스템은 장애 노드를 감지하기 위해 일반적으로 타임아웃에 의존함.
- 잦은 리더 선출은, 리더를 선택하는데 시간을 더 많이 쓰기 때문에 성능을 떨어뜨림.
멤버십과 코디네이션 서비스
- Zookeeper나 etcd 같은 프로젝트는
- "분산 키-값 저장소"나 "코디네이션 설정 서비스"라고 설명됨.
- 작은 양의 데이터를 보관하도록 설계됐고, 이 소량의 데이터는 내결함성을 지닌 TOB 알고리즘을 사용해
모든 노드에 걸쳐 복제됨. - 데이터베이스 처럼 보이지만 목적이 다름. 주 목적은 분산 시스템 간의 일관성과 합의를 보장하는 것
- 이렇기 때문에 HBase, Hadoop YARN, OpenStack Nova, Kafka는 모두 Zookeeper에 의존함.
- ZooKeeper가 재공하는 흥미로운 기능들
- 선형성 원자적 연산
- 연산의 전체 순서화
- 장애 감지
- 변경 알림
작업을 노드에 할당하기
- Zookeeper는 아래의 경우에 유용함
- 리더 선출 필요한 경우
- 파티셔닝된 자원이 있고, 어떤 파티션을 어떤 노드에 할당할지를 결정해야 하는 경우
- (원자적 연산 + 단명 노드 + 알림)을 잘 사용하면
➔ 사람의 개입 없이 애플리케이션이 결함으로부터 자동으로 복구될 수 있다. - 주키퍼는(보통 3~5개) 고정된 수의 노드에서 합의를 수행하고, 수천 대의 클라이언트가 이를 이용
- 그래서 zookeeper 왜 씀? ➔ 합의 알고리즘 구현하기 엄청 빡셈(성공한 기록이 없음)
서비스 찾기
- 특정 서비스에 연결하려면 어떤 IP 주소로 접속해야 하는지 알아내는 용도로도 자주 사용됨.
- 서비스 찾기는 합의는 필요 없지만, 리더 선출은 합의가 필요함.
- 따라서 합의 시스템이 누가 리더인지 안다면, 다른 서비스가 리더를 찾을 때 그 정보를 써도됨.
- 이런 목적으로 어떤 합의 시스템은 읽기 전용 캐시 복제 서버를 지원함.
멤버십 서비스
- 현재 클러스터에 속한 노드가 누구인지(살아 있는지 죽었는지)를 합의 기반으로 관리하는 서비스
- 장애 감지를 합의와 연결하면 노드들은 어떤 노드가 살아 있는 것으로 여겨져야 하는지
혹은 죽은 것으로 여겨져야 하는지에 동의할 수 있다.
'Book > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| 10장. 일괄 처리(Batch Processing) (0) | 2025.10.26 |
|---|---|
| Part3. 파생 데이터 (Derived Data) (0) | 2025.10.26 |
| 8장. 분산 시스템의 골칫거리(The Trouble with Distributed Systems) (0) | 2025.10.13 |
| 7장. 트랜잭션 (0) | 2025.09.29 |
| 6장. 파티셔닝 (0) | 2025.09.20 |