❐ 0. Description
- 트랜잭션 만든 목적
- 데이터베이스에 접속하는 애플리테이션에서 프로그래밍 모델 단순화
- 이번 장에서는
- 문제가 생길 수 있는 여러 예를 조사하고
- 이런 문제를 방지하기 위햇 데이터베이스에서 사용하는 알고리즘을 알아볼 예정
- 특히 동시성 제어 분야를 깊게 다룰 예정
- DB에서 read committed, snaphot isolation, serializability 격리 수준을 어떻게 구현하는지
❐ 1. 애매모호한 트랜잭션의 개념
- 분산 데이터 베이스가 홍보되면서
- 트랜잭션은 확장성의 antithesis(정반대)이며
- 어떤 대규모 시스템이라도 높은 성능과 고가용성을 유지하려면
트랜잭션을 포기해야 하는 믿음이 널리 퍼짐
🌀 1-1. ACID의 의미
ACID
- 원자성 (Atomicity)
- 더 작은 부분으로 쪼갤 수 없는 성질.
- 트랜잭션에서 모든 작업이 전부 실행되거나(All), 전혀 실행되지 않음(Nothing) 을 보장.
- 중간 상태는 존재하지 않음.
- 일관성 (Consistency)
- 데이터가 항상 "좋은 상태(valid state)"에 있어야 한다는 의미.
- 트랜잭션 이전과 이후에 데이터베이스는 항상 consistent한 상태여야 함
- 격리성 (Isolation)
- 동시에 여러 트랜잭션이 실행되더라도, 각 트랜잭션은 다른 트랜잭션의 중간 상태를 볼 수 없어야 함.
- 여러 트랜잭션이 동시에 실행되더라도, 최종 결과가 순차적으로 하나씩 실행된 것과 동일해야 함
- 지속성 (Durability)
- 커밋된 데이터는 영구적임.
복제와 지속성
- 지속성의 의미 변화
- 아카이브 테이프에 기록 ➔ SSD에 기록 ➔ 복제
- 어떤 구현이 가장 좋을까? 완벽한 것은 없음
- 현실에서 절대적 보장을 제공하는 한 가지 기법은 없음.
- 여러 기법을 함께 쓸 수 있으면 그래야 함.
- 항상 이론적인 "보장"은 약간 가볍게 듣는게 현명
🌀 1-2. 단일 객체 연산과 다중 객체 연산
- 단일 객체 트랜잭션은
- DB가 비교적 쉽게 원자성과 격리성을 보장.
- 다중 객체 트랜잭션은
- 동기화가 필요하고, 동시성 문제가 발생하기 쉬움 → 별도 트랜잭션 관리가 필수.
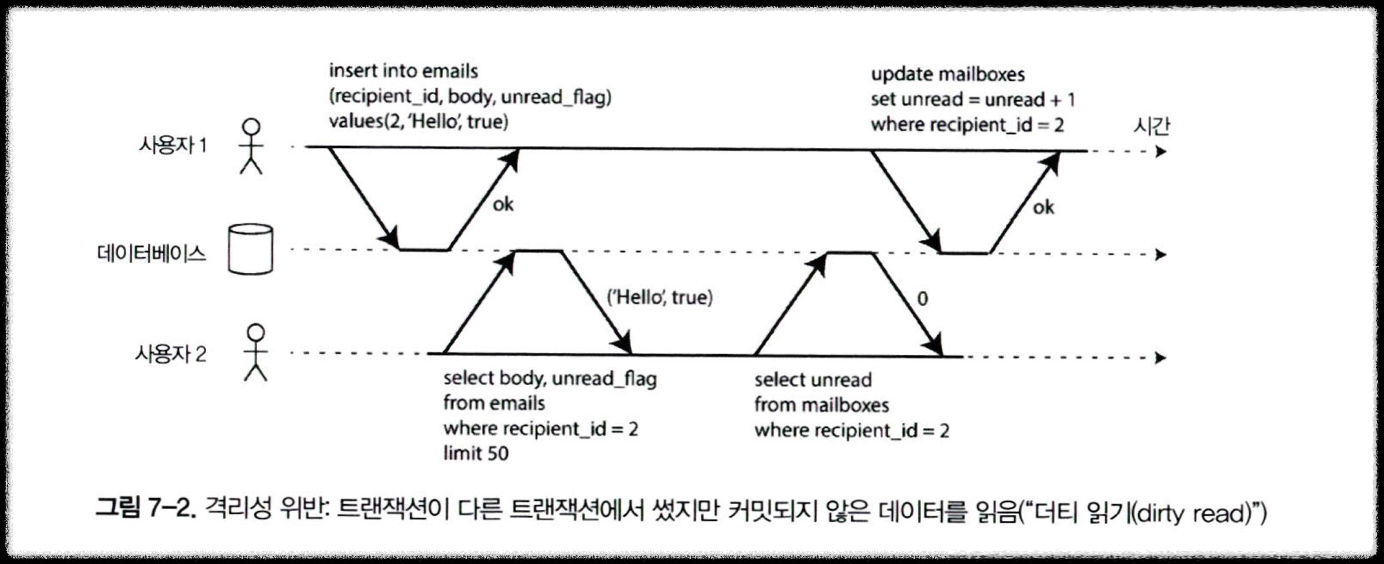
- 사용자 1
- 이메일을 emails 테이블에 insert (읽지 않음: unread_flag = true)
- 이어서 mailboxes 테이블의 unread 카운트를 +1 하려는 중.
- 하지만 아직 커밋 전 상태임.
- 사용자 2
- 같은 시점에 이메일 목록을 조회 → ('Hello', true) 라는 아직 커밋되지 않은 데이터를 읽음.
- 이어서 mailboxes의 unread 카운트를 조회 → 아직 업데이트가 반영되지 않아 0을 읽음.
➔ 트랜잭션이 아직 커밋되지 않은 데이터(중간 상태)를 다른 트랜잭션이 읽었기 때문에 발생. (Dirty read)
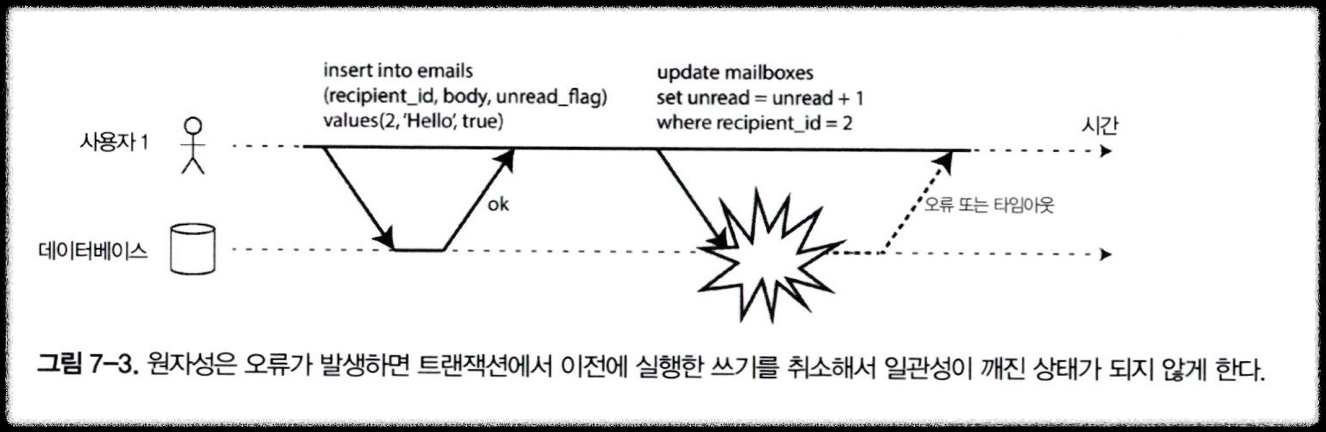
- 다중 객체 트랜잭션은 어떤 읽기 연산과 쓰기 연산이 동일한 트랜잭션에 속하는지 알아낼 수단이 필요
- 관계형 DB:
- 클라이언트 ↔ 서버의 TCP 연결 내에서
- BEGIN TRANSACTION ~ COMMIT 구간에 포함된 연산은 모두 하나의 트랜잭션으로 취급.
- 비관계형 DB:
- 이런 식의 트랜잭션 개념이 없는 경우가 많음.
- 다중 객체 API (예: multi-put)를 제공하더라도 반드시 원자성을 보장하지 않을 수 있음.
- 따라서 일부 키는 성공하고 일부는 실패하는 부분 업데이트 문제 발생 가능.
- 관계형 DB:
단일 객체 쓰기
- 대부분의 저장소 엔진은 단일 객체 수준에서 원자성과 격리성을 보장.
- 원자성: 장애 복구(crash recovery)를 위해 로그(WAL 등)를 사용.
- 격리성: 객체 단위로 락(lock)을 걸어 한 번에 하나의 스레드만 접근 가능하게 보장.
- 더 복잡한 원자적 연산
- 증가 연산 (increment operation)
- read-modify-write를 반복하지 않아도 되는 단일 원자 연산.
- Compare-and-Set (CAS)
- 값이 특정 조건일 때만 쓰기가 반영되도록 하는 연산.
- 동시에 여러 클라이언트가 같은 객체를 갱신하려 할 때 lost update 막을 수 있음.
- 증가 연산 (increment operation)
다중 객체 트랜잭션의 필요성
- 관계형 DB에서 다중 객체 트랜잭션은, 참조가 유효한 상태로 유지되도록 보장해줌.
- 문서 데이터 모델에서는 함께 갱신돼야 하는 값이 동일한 문서 내에 존재하는 경우가 흔함
- 이렇게 단일 문서를 갱신할 때는 다중 객체 트랜잭션이 필요 없음.
- 하지만 비정규화된 정보를 갱신할 때는 한 번에 여러 문서를 갱신해야 함.
- 트랜잭션은 이런 상황에서 비정규화된 데이터가 동기화가 깨지는 것을 방지하는데 매우 유용함.
- 보조 색인이 있는 DB에서는 값을 변경할 때마다 색인도 갱신돼야 함.
- 트랜잭션 관점에서 색인은 서로 다른 데이터베이스 객체
오류와 Abort 처리
- 트랜잭션의 핵심 기능은 오류가 생기면 abort되고 안전하게 재시도할 수 있다는 것
- Abort된 트랜잭션을 재시도하는 것은 간단하고 효과적인 오류 처리 매커니즘 but 완벽하지 않음.
- 커밋 성공을 알리는 도중 네트워크가 끊겼을 때 ➔ 재시도하면 두 번 실행
- 과부화가 오류의 원인이면, 문제를 더 악화시킬 수 있음.
- 등등...
❐ 완화된 격리 수준
🌀 1. 커밋 후 읽기 (Read Committed)
- 가장 기본적인 수준의 트랜잭션 격리
- Dirty Read X
- Dirty Write X
더티 읽기 방지
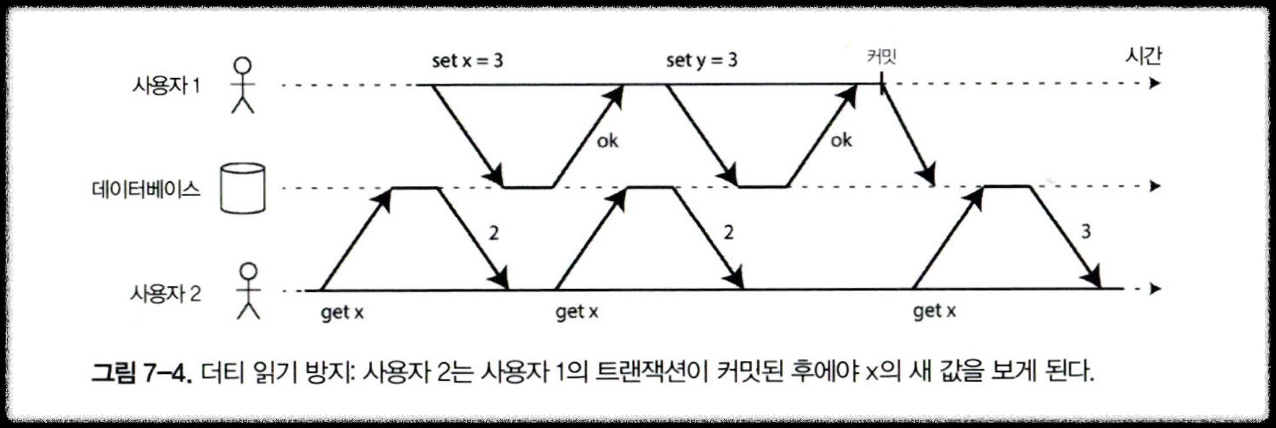
- Dirty Read : 커밋되지 않은 데이터를 읽는 행위
더티 쓰기 방지

- 더티 쓰기 : 두 개의 트랜잭션이 같은 객체를 동시에 수정할 때 발생.
- 더티 쓰기 방지 방법
- 먼저 쓴 트랜잭션이 커밋되거나 abort 될 때까지 두 번째 쓰기를 지연시키는 방법을 사용
커밋 후 읽기 구현
- Row 수준 락을 사용해 더티 쓰기를 방지
- 이 잠금은 Read Committed 모드에서 DB에 의해 자동으로 실행
- 더티 읽기 막으려면?
- 읽기 잠금? 읽기를 하는 여러 트랜잭션이 하나의 쓰기 트래잭션을 기다려야 함.
- read committed하면 됨 (7-4 예제)
🌀 2. 스냅숏 격리와 반복 읽기
Read Skew(non repeatable read) : 논리적으로 일관성이 없는 데이터 읽기

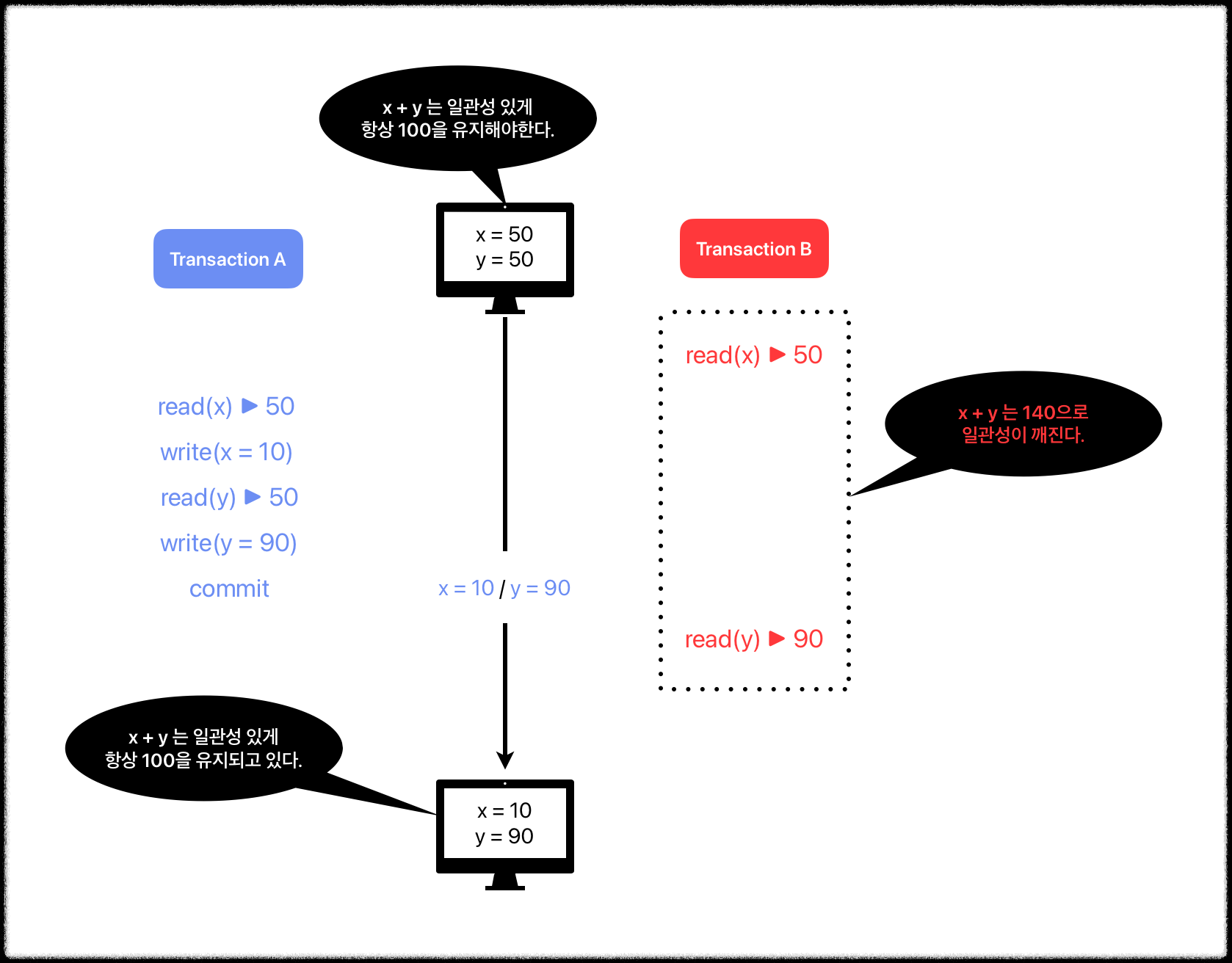
- 물론 앨리스의 경우 시간이 지나면 일관성 있는 계좌를 볼 수 있음.
- 하지만 이런 경우를 허용하기 어려운 경우가 있음.
- 백업
- 백업 과정은 소요시간이 김
- 백업이 실행되는 동안에도 계속 데이터베이스 쓰기는 실행됨
- 따라서, 일부는 과거, 일부는 새 버전을 갖고 있을 수 있음.
- 이런 백어배을 사용해서 복원하면, 비일관성이 영속적이게 됨.
- 분석 질의와 무결성 확인
- DB의 큰 부분을 스캔하는 질의
- 백업
snap shot isolation

- 우선 Snap shot 시작 기준을 잡는다.
- 모든 트랜잭션들은 commit 전 까지의 write 작업을 snap shot에 기록한다. (변경 사항도 기록된다.)
- 다른 한 쪽에서 커밋 했더라도, sanp shot에서 read한다.
- 외부에서 튜플을 조회할 때는 커밋된 데이터를 조회한다.
- write-write conflict 발생 시, 먼저 커밋된 tx가 우선권을 갖는다. (First-committer win)
➔ Snapshot isolation은 위와 같이 동작하며, MVCC(Multi Version Concurrency Control)의 한 종류이다.
snap-shot isolation 구현
- 커밋 후 읽기 격리 처럼 전형적으로 더티 쓰기를 방지하기 위해 쓰기 잠금을 사용
- 읽을 때는 잠금 필요 없음.
일관된 스냅숏을 보는 가시성 규칙
- 가시성 규칙 : 트랜잭션이 객체를 읽을 때 어떤 데이터는 보이고, 어떤 데이터는 보이지 않도록 정하는 규칙.
- 트랜잭션 시작 전 진행 중이던 트랜잭션이 쓴 데이터는 무시
→ 아직 커밋되지 않은 데이터는 보이지 않음. - 트랜잭션 시작 후 다른 트랜잭션이 쓴 데이터는 무시
→ 내가 시작한 이후에 커밋된 변경도 보이지 않음. - 트랜잭션 시작 이전에 커밋된 데이터만 보임
→ 즉, 시작 시점의 스냅숏 기준으로 읽음. - 트랜잭션 외부 데이터(나중에 새로 생성된 객체 등)는 보이지 않음.
- 트랜잭션 시작 전 진행 중이던 트랜잭션이 쓴 데이터는 무시
색인과 스냅숏 격리
- MVCC에서 색인(index)은 각 객체의 여러 버전 중 어떤 버전을 보여줄지 결정.
- 트랜잭션이 색인을 통해 조회할 때, 해당 트랜잭션이 볼 수 있는 버전만 걸러냄.
- 오래된 버전은 가비지 컬렉션 시 삭제.
- 다양한 구현 방식
- PostgreSQL 방식
- 같은 객체의 여러 버전을 같은 페이지(page)에 저장.
- 페이지 단위에서 버전 관리를 최적화.
- 카우치DB(CouchDB), 데이토믹(Datomic), LMDB
- Append-only / Copy-on-write B-트리 사용.
- 페이지를 덮어쓰지 않고, 변경 시 새로운 복사본을 생성.
- 부모 페이지까지 복사하여 새로운 경로를 만들고, 이 경로가 새로운 트랜잭션에서 사용됨.
- 변경 없는 페이지는 그대로 재사용 → 불필요한 복사 최소화.
- PostgreSQL 방식
반복 읽기와 혼란스러운 이름 (Repeatable read and naming confusion)
- snap-shot isolation은 읽기 전용 트랜잭션에서 유용함
- 근데 이를 구현하는 DB에서는 다른 이름을 사용함 (그래서 제목이 naming confusion 인듯..)
- Oracle : 직렬성 (serializable)
- MySQL : 반복읽기 (Repeatable Read)
- 왜 이름이 다 다름?
- SQL 표준에 스냅숏 격리의 개념이 없기 때문
- 표준 SQL을 비판하는 논문에서 언급됨
- 근데 이를 구현하는 DB에서는 다른 이름을 사용함 (그래서 제목이 naming confusion 인듯..)
🌀 3. 갱신 손실 방지 (Preventing Lost Updates)
Lost Update
- 두 트랜잭션의 변경 중 하나가 소실되는 현상
갱신 손실 방지 해결법
- 원자적 쓰기 연산
- 데이터베이스가 제공하는 read-modify-write 패턴을 안전하게 대체하는 연산.
- 애플리케이션 코드에서 직접 값 읽기 → 수정 → 다시 쓰기 과정을 하지 않아도 됨.
- (카운터 증가): updatet counters...
- 객체를 읽을 때 그 객체에 독점적인(exclusive) 잠금 획득해서 구현
- 따라서 갱신이 적용될 때까지 다른 트랜잭션에서 그 객체를 읽지 못하게 됨.
- 이 기법을 커서 안정성(cursor stability)이라고 부르기도 함.
- 명시적인 잠금
- DB가 제공하는 내장 원자적 연산만으로는 갱신 손실(lost update)을 막기 어려운 경우가 있음.
- 이럴 때 애플리케이션은 명시적으로 객체를 잠궈(lock) 문제를 해결할 수 있음.
- 원리:
- 트랜잭션이 어떤 객체를 read-modify-write 하려 할 때,
- 먼저 해당 객체에 잠금을 걸어 다른 트랜잭션이 동시에 접근하지 못하게 차단.
- 첫 번째 트랜잭션이 끝날 때까지 대기.
갱실 손실 자동 감지
- MySQL, 일부 NoSQL은 갱신 손실 감지를 기본 제공하지 않음.
- Compare-and-Set (CAS)
- 트랜잭션 없는 DB에서 자주 쓰는 기법.
- old content가 일치하지 않으면 업데이트 실패 → 충돌 감지.
- 단점: WHERE 절 조건이 빠지면 갱신 손실 방지를 못함.
충돌 해소와 복제
- 여러 노드에서 동시에 쓰기가 발생하면 충돌 가능.
- 해결 방법:
- Sibling 버전 허용 → 충돌된 여러 버전을 모두 저장 후 나중에 병합.
- 애플리케이션이나 특수한 데이터 구조가 충돌 해소를 담당.
- 원자적 연산 사용 → 카운터 증가처럼 교환법칙이 성립하는 경우, 충돌 없이 자동 병합 가능.
- 예: Riak 2.0의 카운터.
- 최종 쓰기 승리 (Last Write Wins, LWW) → 타임스탬프가 가장 늦은 쓰기만 남김.
- 단점: 갱신 손실이 쉽게 발생.
- 많은 DB에서 기본값으로 사용.
- Sibling 버전 허용 → 충돌된 여러 버전을 모두 저장 후 나중에 병합.
🌀 4. 쓰기 skew와 팬텀
쓰기 Skew : 논리적으로 일관성 없는 데이터 쓰기

- 불행하게도 엘리스와 밥이 함께 호출 대기를 상태를 끄는 버튼을 클릭
- 최소 한 명의 의사가 호출대기 해야 하는 요구사항을 위반(논리적 일관성 없음)
- 쉽게 말하면, 다른 객체를 갱신했는데 결과적으로 불변 조건이 깨지는 현상.
방지 방법
- 단일 객체 원자적 연산 → 도움 안 됨.
- 갱신 손실 자동 감지 → 쓰기 스큐는 감지 불가.
- Serializable Isolation → 확실한 해결 법
- 특정 경우에는 명시적인 제약 조건이나 명시적 잠금으로 해결 가능.
쓰기 skew를 유발하는 팬텀
- 팬텀 효과
- 어떤 트랜잭션에서 실행한 쓰기가 다른 트랜잭션의 검색 결과를 바꾸는 효과.
- 스냅숏 격리는 읽기 전용 질의에서는 팬텀을 회피할 수 있음.
- 의사 대기 예제의 경우 읽기 쓰기 트랜잭션에서는 패텀이 쓰기 skew를 유발 할 수 있음.
충돌 구체화
- 데이터베이스에 추가 테이블을 만들어서 인위적으로 잠금 객체를 도입하는 방식.
- 즉, 원래는 없던 "충돌 지점"을 명시적인 행(row)으로 표현해놓고 잠금으로 제어.
- 예시
- 회의실 예약을 위해 "회의실 × 시간 슬롯" 조합 테이블을 생성.
- 각 로우 : 특정 회의실이 특정 시간 동안 사용됨을 의미.
- 예약 트랜잭션은 원하는 시간 슬롯에 대해 SELECT … FOR UPDATE로 잠금을 걸고 예약을 삽입.
- 이렇게 하면 중복 예약 방지 가능.
- 주의: 이 테이블은 실제 예약 정보 저장이 목적이 아니라, 잠금 충돌을 강제로 드러내기 위한 장치일 뿐.
❐ 직렬성
🌀 1. 실제적인 직렬 실행
직렬 실행
- 트랜잭션을 순차적으로 실행하는 방법
트랜잭션을 stored procesure 안에 캡슐화

- 애플리케이션 로직 전체를 DB 안의 스토어드 프로시저로 제출.
- DB 내부에서 순차적으로 실행되므로 네트워크 지연이 없음.
- 모든 데이터가 DB 메모리 안에 있으므로 매우 빠르게 실행 가능.
Stored procesure의 장단점
- 장점
- DB 내부에서 실행 → 빠른 성능
- 네트워크 왕복 없이 DB 안에서 바로 실행되므로 지연이 적음.
- 배포 및 관리 용이
- 로직이 DB에 저장되므로 클라이언트 애플리케이션을 다시 배포할 필요가 없음.
- 보안 및 권한 관리
- 특정 연산을 스토어드 프로시저를 통해서만 실행하도록 제한 가능.
- 복잡한 트랜잭션 처리에 적합
- 여러 쿼리를 묶어 원자적으로 실행 가능.
- DB 내부에서 실행 → 빠른 성능
- 단점
- 언어 및 개발 환경 제약
- PL/SQL, T-SQL 등 DB 종속적 언어 사용 → 유지보수와 개발 생산성 낮음.
- 현대는 Java, C#, Groovy, Lua 등 범용 언어와 연동되는 경우도 있지만 여전히 제약 존재.
- 확장성 문제
- 스토어드 프로시저는 특정 DB 인스턴스 안에서만 실행 → 분산 환경에서 부하 분산이 어렵다.
- 복제 환경 문제
- 스토어드 프로시저가 쓰기 연산을 포함하면, 복제된 노드 간 결정이 동일해야 함 → 충돌 가능.
- 언어 및 개발 환경 제약
🌀 2. 2단계 잠금 (2PL)
2PL
- 데이터베이스 관리 시스템에서 트랜잭션의 serializability를 보장하기 위한 동시성 제어 기법 중 하나
- 이 프로토콜은 트랜잭션이 데이터에 접근할 때 사용하는 lock의 획득과 해제를 두 단계로 나누어 관리
- 따라서 트랜잭션에서 모든 locking operation이 최초의 unlock operation보다 먼저 수행됨을 보장
2PL 잠금 구현
- MySQL에서는 직렬성 격리 수준을 구현한데 사용됨.

2차 잠금의 성능
- 트랜잭션 처리향과 질의 응답 시간이 크게 나빠짐.
- 부분적으로는 잠금을 획득하고 해제하는 오버헤드 때문이지만
- 중요한 원인은 동시성이 줄어드는 것임.
- 교착 상태가 발생할 수 있음.
서술 잠금 (Predicate lock)
- 직렬성 격리를 쓰는 DB는 팬텀을 막아야 함.
- 서술 잠금은
- 공유/독점 잠금과 비슷하게 동작하지만
- 특정 객체에 속하지 않고 특정 검색 조건에 부합하는 모든 객체에 속함
- DB에 아직 존재한지 않지만 미래에 추가될 수 있는 객체(팬텀)에도 적용할 수 있음.
- 근데 이거 잘 동작 안 함.
- 진행중인 트랜잭션들이 획득한 잠금이 많으면
조건에 부합하는 잠금을 확인하는데 시간이 오래 걸리기 때문
- 진행중인 트랜잭션들이 획득한 잠금이 많으면
색인 범위 잠금
- 서술 잠금이 잘 동작하지 않아서 실제로는 색인 범위 잠금(다음 키 잠금)을 구현함
- 예약 예시
- 어떤 방법을 쓰든 간략화한 검색 조건이 색인 중 하나에 붙음
- 다른 트랜잭션ㅇ니 같은 방을 사용하거나 시간이 겹치는 예약을
삽입,갱신,삭제하길 원한다면 색인의 같은 부분을 갱신해야 함. - 이 과정에서 공유 잠금을 발견하고 잠금이 해제될 때까지 기다리게 됨.
- 이 방법을 쓰면 팬텀 쓰기 skew로 부터 보호해주는 효과있음.
- 색인 범위 잠금은 서술 잠금보다 정밀하지 않지만 오버헤드가 훨씬 더 낫기 때문에 좋은 타협안은 아님
🌀 3. 직렬성 스냅숏 격리 (SSI)
지금까지는..
- 암울한(bleaked) 뭐 그런 이야기를 했음.
- 성능이 좋지 않다거나, 확장성이 떨어진다거나 등등...
직렬성 스냅숏 격리 (Serializable snapshot isolation, SSI)
- 암울한 현실은 이제 그만!
- 완전한 직렬성을 제공함. (스냅숏 격리에 비해 아주 조금의 성능 손해만 있음)
- 나름 최신 (2008년에 처음 기술됐음)
비관적(pessimistic) 동시성 제어 대 낙관적(optimistic) 동시성 제어
- 2PL은 비관적 동시성 제어 메커니즘임.
- 직렬 실행은 어떤 면에서 보면 극단적으로 비관적임.
- SSI는 낙관적 동시성 제어 기법
- 낙관적 동시성 제어 기법은..
- 경쟁이 심하면 abort 시켜야 할 트랜잭션의 비율이 높아지므로 성능이 떨어짐.
- (최대 처리량에 근접한 경우) 재시도 되는 트랜잭션으로부터 발생하는 부가적인 트랜잭션 부하가
성능을 저하시키는 요인 - 처리량에 여유가 있으면, 비관적 동시성 제어보다 성능이 좋음.
뒤처진 전제에 기반한 결정(Decision based on outdated premise)
- 트랜잭션은 어떤 전재를 기반으로 어떤 동작을 함.
- 나중에 해당 트랜잭션이 커밋하려고 할 때 원래 데이터가 바뀌어서 그 전제가 더 이상 참이 아닐 수 있음.
- 즉, 트랜잭션에서 실행하는 읽기와 쓰기 사이에는 인과관계가 있음.
→ snapshot을 기반으로 의사결정을 하면 잘못된 결과를 낼 수 있음.
읽기 결과가 변경됐음을 탐지할 수 있는 방법
1. 오래된 MVCC 읽기 감지하기 (Detecting stale MVCC reads)

- 위와 같은 현상을 방지하려면
- DB는 MVCC 가시성 규칙에 의해 한 트랜잭션이, 다른 트랜잭션의 쓰기를 무시하는 경우를 추적(track)해야 함.
- 트랜잭션이 커밋하려고 할 때, DB는 무시된 쓰기 중에 커밋된게 있는지 확인해야 함.
- 커밋된 게 있다면 트랜잭션은 abort 되어야 함.
- 왜 오래된 읽기를 했을 때 바로 abort안함? (by. GPT)
- 읽기 전용 트랜잭션은 Abort할 필요 없음
- 예: 트랜잭션 43이 단순히 읽기만 수행하는 경우
- 쓰기를 전혀 하지 않기 때문에 쓰기 스큐(Write Skew) 위험이 없음.
- 따라서 오래된 데이터를 읽었다고 해서 무조건 Abort할 이유가 없다.
- DB는 커밋 전까지는 해당 트랜잭션의 쓰기 여부를 알 수 없음
- 트랜잭션 43이 읽기를 실행하는 순간, 나중에 쓰기를 동반할지 아닐지는 아직 알 수 없다.
- 게다가 이전 트랜잭션(예: 42)이 이미 Abort되었을 수도 있고, 아직 커밋되지 않았을 수도 있다.
- 결국 “오래된 읽기”인지 여부는 커밋 시점에서만 확정 가능하다.
- 불필요한 Abort를 피하는 것이 중요
- 단순히 오래된 읽기가 감지되었다고 즉시 Abort해 버리면, 실제로는 아무 문제도 없었을 수 있음.
- 이는 불필요하게 트랜잭션을 실패시켜 성능을 떨어뜨림.
- 따라서 SSI(Serializable Snapshot Isolation)에서는 최종적으로 실제 충돌이 확인될 때만 Abort를 수행한다.
- 스냅숏 격리의 특성 유지
- 읽기 작업은 가능한 오래 실행될 수 있도록 보장해야 함.
- 즉, “읽고 있는 동안 다른 트랜잭션 때문에 불필요하게 중단되지 않게” 하는 것이 스냅숏 격리의 장점.
- 그래서 시스템은 커밋 시점까지 기다린 뒤, 정말로 문제가 되는 경우에만 Abort를 결정한다.
- 읽기 전용 트랜잭션은 Abort할 필요 없음
2. 과거의 읽기에 영향을 미치는 쓰기 감지하기
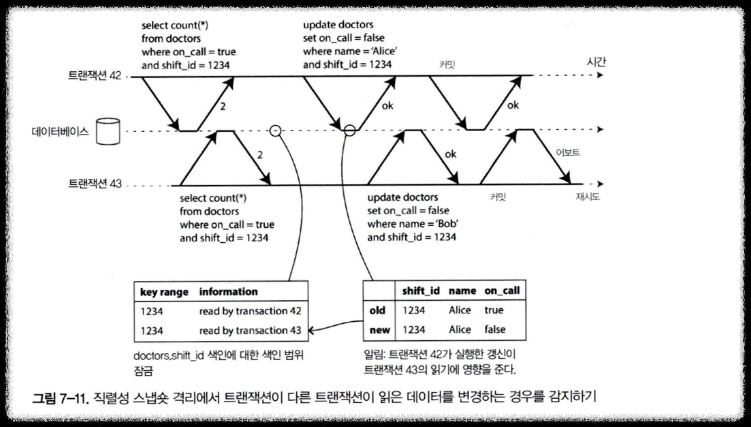
- 고려해야 할 2번째 케이스 : 데이터를 읽은 후 다른 트랜잭션에서 그 데이터를 변경할 때
- 예제
- 트랜잭션42,43 모두 대기 순번 1234 동안의 호출 대기 의사를 검색
- 트랜잭션42
- Alice 상태 변경 (on_call : true → false)
- commit
- 트랜잭션43
- Bob 상태 변경 (on_call : true → false)
- commit
- abort (다른 트랜잭션이 읽은 데이터를 변경했기 때문)
SSI의 성능
- 비교군 : 2PL
- 트랜잭션이 다른 트랜잭션들이 잡고 있는 잠금을 기다리느라 차단될 필요가 없다는 것
- 비교군 : 순차 실행
- 단일 CPU 코어의 처리량에 제한되지 않음.
- ex. 파운데이션 DB
- Abort 비율은 SSI의 전체적인 성능에 큰 영향을 미침
'Book > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| 9장. 일관성과 합의 (Consistency and Consensus) (0) | 2025.10.17 |
|---|---|
| 8장. 분산 시스템의 골칫거리(The Trouble with Distributed Systems) (0) | 2025.10.13 |
| 6장. 파티셔닝 (0) | 2025.09.20 |
| 5장. 복제 (0) | 2025.09.14 |
| Part2. 분산 데이터 (0) | 2025.09.13 |