❒ Description
HTTP가 어떻게 TCP 커넥션을 사용하고, TCP 커넥션의 문제점과 이런 부분을 어떻게 관리하는지
이해하고 공부해보자!
❒ 네트워크 지연의 이유
HTTP는 TCP 바로 위에 있는 계층이기 때문에 HTTP 트랜잭션의 성능은 그 아래 계층인 TCP 성능에
영향을 받는다. 즉, 대부분의 HTTP 네크워크 지연은 TCP 네크워크의 지연 때문에 발생한다.
그럼 정확히 어떤 이유 때문에 지연이 발생하는지 알아보자.
1. Hand shake 지연
크기가 작은 HTTP 트랜잭션은 50% 이상의 시간을 TCP를 구성하는데 쓴다.
왜냐면 핸드셰이크 과정에서 패킷이 오고 가기 때문이다.
2. 확인 응답(ACK) 지연
확인 응답은 크기가 작아서 같은 방향으로 송출되는 데이터 패킷에 확인 응답을 편승(Piggyback)시킨다.
이렇게 함으로써 네트워크를 좀 더 효율적으로 사용한다.
확인 응답 지연 알고리즘의 과정은 다음과 같다.
- 송출할 확인 응답을 특정 시간 동안 버퍼에 저장
- 확인응답을 편승시킬 송출 데이터 패킷을 찾는다.
- 일정 시간동안 찾지 못 할 경우 별도 패킷을 만들어서 보낸다.
하지만 HTTP 트랜잭션은 요청/응답 이 두 가지로 이루어져서 확인 응답을 편승시킬 패킷이 많지가 않다.
결과적으로 지연 알고리즘으로 인한 네크워크 지연이 자주 발생한다.
3. Slow Start
TCP 커넥션은 시간이 지나면서 자체적으로 튜닝이 된다.
처음에는 커넥션의 최대 속도를 제한하고, 데이터가 성공적으로 전송됨에 따라 속도 제한을 높여간다.
이렇게 조율하는 것을 TCP Slow start라고 한다. 이 과정은 네트워크의 갑작스러운 부하와 혼잡을
방지하기 위함이다.
새롭게 생성된 커넥션 보다 튜닝된 커넥션이 속도가 더 빠르기 때문에 HTTP는 이렇게 이미 튜닝된
커넥션을 사용하는 기술이 있다.
4. Nagle 알고리즘 & TCP_NODELAY
네이글 알고리즘은 TCP 네트워크에서 작은 패킷이 과도하게 발생하는 것을 방지하며 네트워크의
효율성을 높이기 위해 사용된다. 이 알고리즘은 작은 데이터들이 연속적으로 전송되지 않도록
세그먼트가 최대 크기가 되지 않으면 전송하지 않는다.
단, 모든 패킷이 확인응답을 받았다면 최대 크기가 되지 않았더라도 전송한다. 다른 패킷들이 아직
전송 중이면 데이터는 버퍼에 저장된다. 아마도 이 버퍼는 socket에 있는 버퍼로 생각된다.(커널의 소켓 송신 버퍼)
이 알고리즘에도 문제점이 있다.
- 애초에 크기가 작은 데이터는 추가적인 데이터를 기다리며 전송 지연된다.
- 확인응답 지연 알고리즘과 같이 사용될 경우 성능이 형편없다.
HTTP 애플리케이션은 성능 향상을 위해 HTTP 스팩에 TCP_NODELAY 파라미터 값을 설정하여
네이글 알고리즘을 비활성화 할 수 있다. 단, 이 설정을 했다면 작은 크기의 패킷이 너무 많이 생기지
않도록 큰 크기의 데이터 덩어리를 만들어야 한다.
작은 패킷이 너무 많이 생성되면 아래와 같은 문제가 생길 수 있다.
- 네트워크 혼잡
- 오버헤드 증가 - 패킷이 많아질 수록 더 많은 헤더가 필요하기 때문
- 전송 효율 저하
5. TIME_WAIT의 누적과 포트 고갈
TCP 커넥션의 End-point에서 커넥션을 끊으면 TCB에 IP와 Port 번호를 저장한다.
이 정보는 같은 주소와 포트 번호를 사용하는 새로운 TCP 커넥션이 일정 시간 동안에는 생성되지
않도록 하기 위한 것으로, 보통 세그먼트의 최대 생명주기에 두 배 정도의 시간 동안 유지된다.
만약 바로 동일한 스펙의 커넥션이 만들어지게 되면 이전 커넥션의 패킷이 새로운 커넥션에 삽입 될
수도 있기 때문이다.
❒ Http Connection
1. 병렬 커넥션
병렬 커넥션의 개념은 각 커넥션의 지연 시간을 겹치게 하자는 것이다. 이렇게 하면 직렬 커넥션과 속도는 같아도
사용자 입장에서 더 빠르게 느껴질 수 있다. 근데 이게 항상 빠른건 아니기도 하고 몇몇 문제가 있다.
- 각 트랜잭션마다 새로운 커넥션을 맺고 끊기 때문에 시간과 대역폭이 소요된다.
- 대역폭이 낮은 경우 성능상 장점이 없다.
- 실제 연결할 수 있는 병력 커넥션은 한계가 있다. (브라우저는 대부분 4개)
다수의 커넥션은 메모리를 많이 차지하기 때문에 자체적인 성능 이슈가 있다.
서버 입장에서는 다수의 클라이언트의 커넥션을 수용해야 하는데, 100명의 클라가 각가 100개의 커넥션을
연결하게 된다면? 서버 성능에 문제가 생긴다. 서버는 과도한 수의 커넥션이 맺어질 경우 임의로그 커넥션을
끊을 수 있다.
2. 지속 커넥션
지속 커넥션을 사용하면 TCP의 slow-start로 인한 지연을 피함으로써 더 빠르게 데이터를 전송할 수 있다.
위에서 병렬 커넥션에 문제점이 있었는데, 지속 커넥션은 병렬 커넥션과 같이 썼을 때 가장 효과적이다.
두 가지 타입이 있는데 HTTP/1.0에서는 keep-alive, HTTP/1.1에서는 지속 커넥션이 있다.
2-1. HTTP/1.0 keep-alive
여기서는 keep-alive를 헤더에 포함해야 한다. 이렇게 `Connection: Keep-Alive`.
여기에는 몇 가지 제한과 규칙이 있다. 그 중 가장 중요해 보이는 2가지만 정리한다.
- 커넥션이 끊어지기 전에 엔터티 본문의 길이를 알 수 있어야 한다.
- 잘못된 Content-length 값을 보내게 되면, 트랜잭션이 끝나는 시점에
기존 메시지의 끝과 새로운 메시지의 시작점을 정확히 알 수 없기 때문이다.
- 잘못된 Content-length 값을 보내게 되면, 트랜잭션이 끝나는 시점에
- 프락시와 게이트웨이는 메시지를 전달하거나 캐시에 넣기 전에 Connection 헤더에
명시된 모든 헤더 필드와 connection 헤더를 제거해야 한다.
2번의 문제는 Dumb Porxy에서 잘 드러난다.
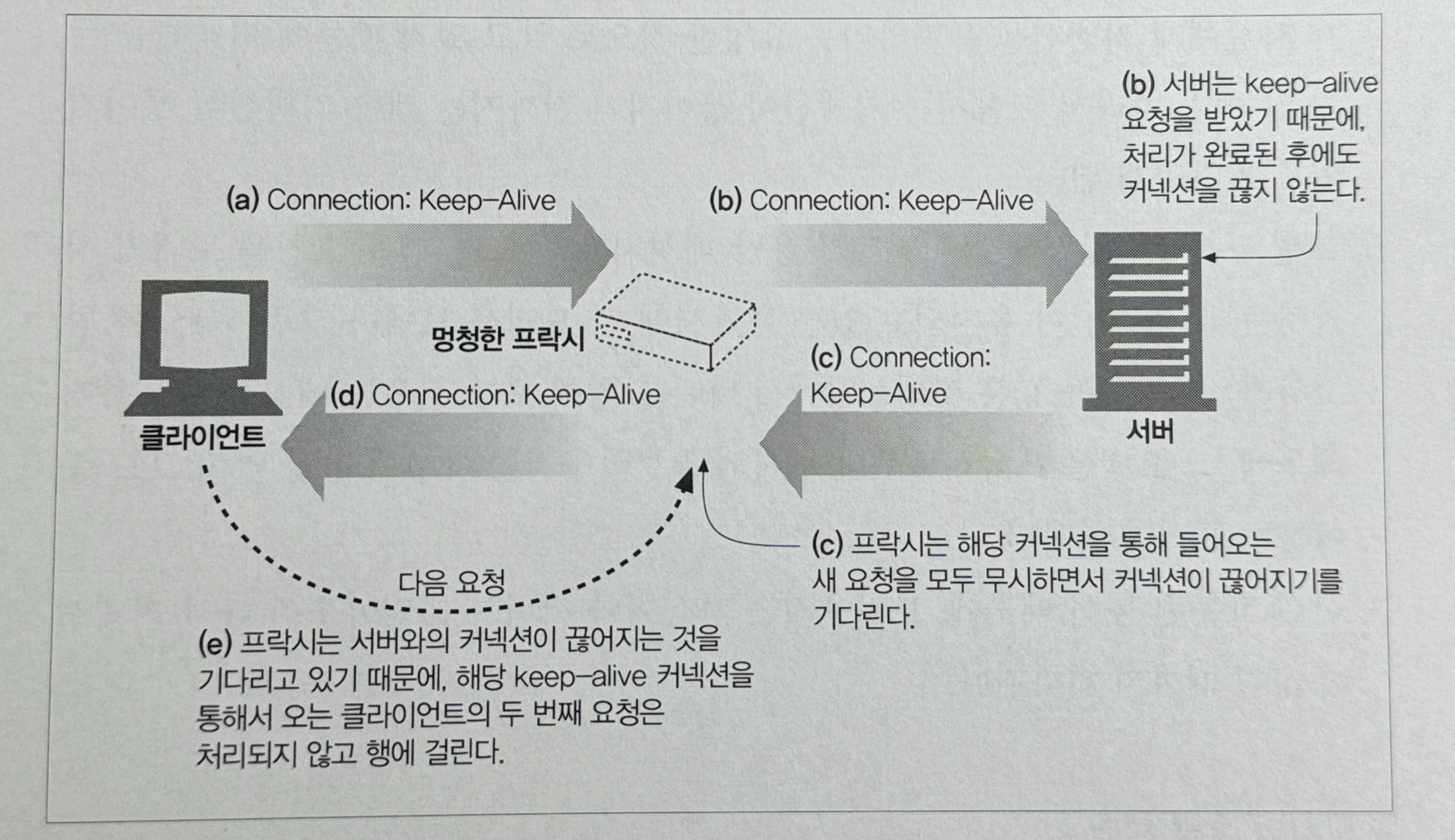
- 클라가 Proxy와 keep-alive를 맺기 위해 Connection 헤더를 전달한다.
- Proxy는 멍청해서 Connecion 헤더를 이해하지 못하고 서버한테 고대로 전달한다. (문제 발생)
- 서버는 Proxy가 keep-alive를 맺자고 하는줄 안다. 그리고 Connection 헤더를 포함하여 응답한다.
- Proxy는 클라에게 서버에게 받은 응답을 그대로 전달한다.
이 후에 Proxy는 서버가 커넥션을 끊기를 기다린다. 하지만 서버는 Proxy가 자신에게 커넥션을 유지하기를
요청한 것으로 알고 있기 때문에 커넥션을 유지한다. 결과적으로 Proxy는 커넥션이 끊어지기 전까지 서버가
커넥션을 끊어주길 기다린다.
이런 경우에 클라가 다른 요청을 보내면 어떻게 될까?
- 클라가 Request2를 보낸다.
- Proxy는 같은 커넥션 상의 다른 요청(Request2)은 예상하지 못한다.
- 결국 Request2는 무시되고, 브라우저는 무한 로딩에 걸린다. (그러다가 커넥션 끊기거나 타임아웃)
위와 같은 잘못된 통신을 피하기 위해서는 Proxy는 Connection 헤더와 명시된 내용들을 절대 다음 hop으로
전달해서는 안된다. 이 뿐만 아니라 Proxy-Authenticate, Proxy-Connection, Transfer-Encoding 등과
같은 hop-by-hop 헤더들은 절대절대 다음으로 전달되거나 캐싱되서는 안된다.
그래서 이 문제를 해결하기 위해 Intelligent Proxy가 나왔다.
여기서는 Proxy-Connection이라는 확장 헤더를 사용하고 읽을 수 있다. 그리고 Intelligent Proxy는
Proxy-Connection를 Connection 헤더로 변경한다.
근데 이 방식은 `Client-Proxy-Server` 구조, 즉 하나의 Proxy가 있을 때만 동작한다.
그래서 HTTP/1.1에서는 keep-alive 커넥션을 지원하지 않는다.
2-2. HTTP/1.1 지속 커넥션
HTTP/1.1에서는 별도의 설정을 하지 않는 한 기본적으로 활성화가 되어 있다.
대신 커넥션을 끊을라면 `Connection: close` 헤더를 명시해 줘야한다.
3. 파이프라인 커넥션
HTTP/1.1은 지속 커넥션을 통해서 요청을 pipelining 할 수 있다.
파이프라인 커넥션을 사용하기 위해서는 몇 가지 제약 사항을 지켜야한다.
- 클라이언트는 사용하려는 커넥션이 지속 커넥션인지 확인해야 한다.
- HTTP 요청에 대한 응답은 순서 대로 와야 한다. (HOL Blocking 발생할 수 있음.)
- 클라이언트는 커넥션이 끊어져 실패한 요청에 대해 재요청할 수 있어야 한다.
- POST와 같은 비멱등(nonidempotent) 요청은 재요청 하면 안된다.
❒ HOL (Head Of Line) Blocking
HOL Blocking은 네트워크에서 같은 큐에 있는 패킷이 그 첫 번째 패킷에 의해 지연될 때 발생하는
성능저하 현상을 말한다. 이 현상으로 패킷의 처리속도가 저하되고 최악의 경우에는 Drop될 수 있다.
또한 HOL Blocking은 특히 네트워크 스위치와 라우터에서 성능 저하를 일으킬 수 있다.
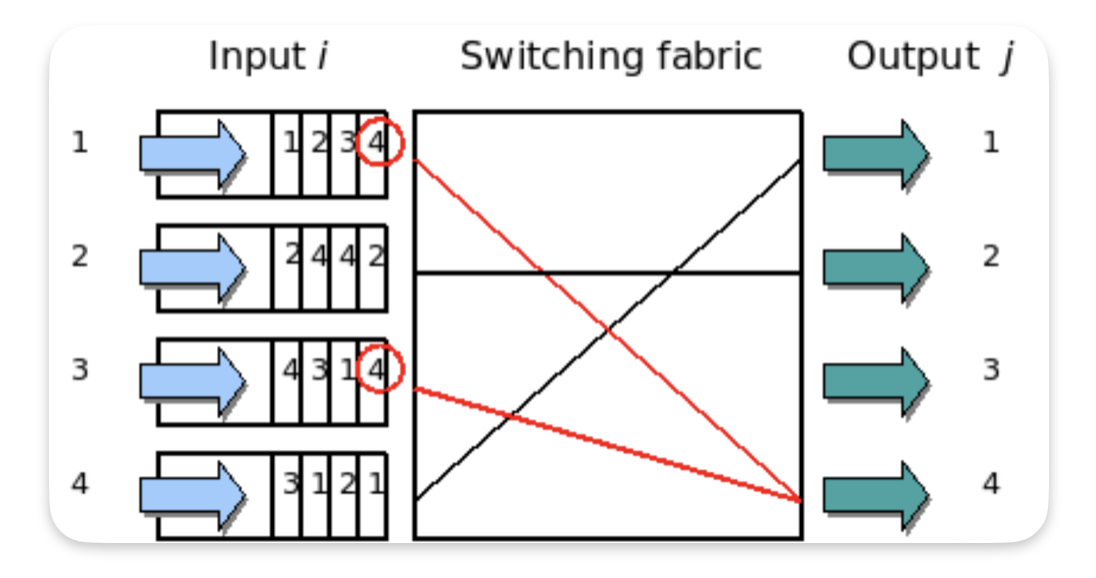
위 이미지는 HOL Blocking의 예시를 보여준다. 첫 번째와 세 번째 input의 맨 앞 패킷은 모두 같은 출력 포트인,
output4로 나가려고 경쟁하고 있다. 이때 Switching fabric이 이번 time slot에는 input3의 패킷만 output4로
보내기로 선택하면, input1의 패킷은 같은 time slot에서는 전송되지 못하고 큐 맨 앞에서 그대로 대기하게 된다.
1. Virtual Output Queuing (VOQ, 가상 출력 큐)
• 설명
HOL Blocking을 해결하기 위해 가장 널리 사용되는 방법 중 하나다.
VOQ에서는 각 입력 포트에서 출력 포트별로 별도의 큐를 생성한다.
• 어떻게 작동하는지
입력 포트마다 각 출력 포트로 가는 패킷들을 위한 개별 큐가 만들어진다.
이 방식으로 특정 출력 포트로 가는 패킷이 대기 중일 때, 다른 출력 포트로 가는 패킷들이 전송되는 것을 막지 않게 된다.
• 장점
HOL Blocking 문제를 근본적으로 해결할 수 있다.
2. 큐 스케줄링 알고리즘 (Scheduling Algorithms)
• 설명
스케줄링 알고리즘을 통해 입력 큐의 패킷들을 효율적으로 관리하여 HOL Blocking을 줄이는 방법
• 어떻게 작동하는지
각 입력 포트에서 어느 패킷을 먼저 전송할지 결정하는 알고리즘을 통해 경쟁 상황을 조정하고,
가능한 많은 패킷이 동시에 전송될 수 있도록 한다.
• 장점
스위치의 성능을 최적화하고, HOL Blocking을 완화
3. 패킷 재정렬 (Packet Reordering)
• 설명
특정 조건 하에서 패킷의 순서를 바꾸는 방식으로, 앞에서 막힌 패킷을 뒤로 보내거나 다른 큐로 옮기는 방법
• 어떻게 작동하는지
스위칭 장치나 네트워크 장치가 입력 패킷의 순서를 유동적으로 변경하여, HOL Blocking을 줄일 수 있다.
• 장점
HOL Blocking 문제를 줄이는 데 도움을 줄 수 있지만, 패킷 순서 보장에 주의해야 한다.
4. 입출력 버퍼 스위치 (Input-Buffered and Output-Buffered Switches)
• 설명
스위치의 구조를 개선하여 HOL Blocking 문제를 줄이기 위한 접근 방식
• 어떻게 작동하는지
입력 버퍼와 출력 버퍼 모두를 활용하여 데이터 전송을 더 유연하게 처리
• 장점
스위치 성능을 개선하고, 특정 상황에서 HOL Blocking 문제를 줄일 수 있다.
5. 서브슬롯 처리 (Sub-Slot Processing)
• 설명
시간을 더 작은 슬롯으로 나누어, 같은 슬롯 내에서 여러 패킷을 순차적으로 처리하는 방법입니다.
• 어떻게 작동하는지
한 슬롯을 더 작은 단위로 나누어 여러 패킷을 짧은 시간 내에 처리함으로써, HOL Blocking을 줄인다.
• 장점
패킷 전송 효율을 높이고 HOL Blocking의 영향을 줄일 수 있다.
6. 멀티큐 구조 (Multiple Queue Structures)
• 설명
하나의 큐가 아닌 여러 큐를 활용해 패킷을 분산 처리하는 방식
• 어떻게 작동하는지
여러 큐에 패킷을 분산 배치하고, 각 큐에서 독립적으로 전송되도록 한다.
• 장점
특정 큐에서 발생하는 HOL Blocking의 영향을 다른 큐로 분산시켜 줄인다.
이러한 방법들은 네트워크 장비의 성능을 최적화하고, HOL Blocking으로 인한 전송 지연을 최소화하기 위한 기술들이다.
❒ Graceful Termination (우아한 끊기)
1. 우아한 끊기란?
이 내용은 TCP 제대로 이해하기에서 공부했던 내용이 일부 중복된다.
여기에는 전체 끊기와 절반 끊기 방법이 있다.
전체 끊기 할 경우 소켓의 양방향 통신을 완전히 종료하는 것을 의미한다. 즉, 더 이상 데이터를
보내지도 받지도 않는다. 이 경우 socket-buffer도 지워지며 연결이 완전히 close된다.
절반 끊기 할 경우에는 출력 쪽을 끊는 것이 안전하다.
왜냐면 입력 쪽은 OS-Buffer에 있는 데이터를 모두 receive한 후에 출력 쪽 커넥션이 끊긴 것을
알 수 있다. 즉, 유실되는 데이터가 없어서 안전하다.
반면에 입력 쪽을 끊을 경우에는 다음과 같은 문제가 생긴다.
클라이언트가 입력 커넥션이 끊긴 서버에 요청을 보내게 되면, OS는 connection reset by peer
메시지를 클라한테 보낸다. OS는 이를 심각한 이슈로 인지하고 Buffer에 저장된, 즉 아직 receive되지
않은 데이터를 모두 삭제한다.
Graceful termination을 위해서 Application은 스트림의 끝을 식별하기 위해 입력 채널의 상태를
주기적으로 검사해야 한다.
2. Spring Boot에서는 어떻게?
TODO : 별도로 포스팅하기.
❒ 예상 면접 질문
1. HTTP 트랜잭션의 성능이 저하되는 이유는?
애플리케이션 계층은 전송 계층 바로 위에 있기 때문에 전송 계층의 영향이 큽니다.
TCP hand shake 과정, 확인응답 지연, slow-start, 네이글 알고리즘 활성 여부 등이 있습니다.
1-1. 확인응답 지연과 네이글 알고리즘이 어떻게 영향을 미치는지 자세히 설명해주세요.
확인응답은 크기가 작아서 같은 방향으로 송출되는 데이터 패킷에 편승(Piggyback)되는데,
HTTP 트랜잭션은 요청/응답 구조로 되어 있기 때문에 편승시킬 패킷이 많지가 않습니다.
결국 일정시간동안 송출데이터 패킷을 찾지 못하면, 별도의 패킷을 보내게 됩니다.
네이글 알고리즘은 TCP 네크워크 상에 작은 패킷이 과도하게 발생하는 것을 방지하기 위해
사용되는데, 이 알고리즘은 최대 크기의 세그먼트가 되지 않으면 데이터를 전송하지 않습니다.
따라서 애초에 크기가 작은 데이터는 추가적인 데이터를 기다리며 전송이 지연됩니다.
1-2. Slow-Start가 뭔가요?
TCP 커넥션은 시간이 지남에 따라 자체적으로 튜닝이되는 특징을 갖고 있습니다.
처음에는 커넥션의 최대 속도를 제한하고, 데이터가 성공적으로 전송되는 것에 따라 점차적으로
속도제한을 높입니다. 이렇게 조율하는 과정을 Slow-start라고 합니다.
1-3. HTTP 트랜잭션 성능 저하를 해결하기 위한 방법은 어떤 것들이 있나요?
HTTP 트랜잭션의 성능 저하를 해결하기 위한 다양한 방법이 존재합니다. 대표적으로 다음과 같은 기술들이 있습니다:
1. 병렬 커넥션
병렬 커넥션은 여러 HTTP 요청을 동시에 처리하기 위해 여러 TCP 연결을 사용하는 방법입니다. 이를 통해 각 연결의 지연 시간을 겹치게 할 수 있어 성능이 향상될 수 있습니다. 하지만 대역폭이 낮거나 연결에 제한이 있는 환경에서는 성능상의 이점이 크지 않을 수 있습니다. 또한, 브라우저마다 한 도메인에 대해 허용되는 동시 연결 수에 제한이 있기 때문에(보통 4-6개) 이 방법의 효과는 제한적입니다.
2. 지속 커넥션 (Persistent Connection)
지속 커넥션은 하나의 TCP 연결을 통해 여러 HTTP 요청과 응답을 처리하는 방법입니다. 이 방식은 새로운 연결을 맺을 때 발생하는 TCP의 slow-start 문제를 완화하여 성능을 향상시킵니다. HTTP/1.0에서는 Connection: keep-alive 헤더를 사용하여 지속 커넥션을 유지했으나, 몇 가지 제약이 있었습니다. HTTP/1.1에서는 지속 커넥션이 기본 설정으로 활성화되어 있으며, Connection: close를 사용하여 명시적으로 연결을 종료할 수 있습니다.
3. 파이프라이닝 (Pipelining)
파이프라이닝은 지속 커넥션을 활용하여, 하나의 연결에서 여러 HTTP 요청을 연속적으로 보내고 응답을 순차적으로 받는 기술입니다. 이를 통해 네트워크 지연 시간을 줄일 수 있습니다. 하지만, 파이프라이닝은 응답이 순차적으로 도착해야 한다는 제약이 있기 때문에 HOL(Head of Line) Blocking이 발생할 수 있습니다. 이로 인해 일부 서버와 클라이언트는 이 기능을 비활성화하거나 지원하지 않습니다.
4. HTTP/2와 멀티플렉싱 (Multiplexing)
HTTP/2에서는 스트림과 멀티플렉싱을 도입하여 한 커넥션에서 다수의 요청과 응답을 동시에 처리할 수 있게 했습니다.
이를 통해 HOL Blocking 문제를 해결하고, 트랜잭션 성능을 크게 향상시켰습니다. 또한, 헤더 압축을 통해 데이터 전송량을 줄이고, 서버 푸시를 통해 추가적인 리소스를 미리 클라이언트에게 전송할 수 있습니다.
5. 콘텐츠 전송 네트워크 (CDN)
CDN을 활용하면 클라이언트와 가장 가까운 서버에서 콘텐츠를 제공받을 수 있어 지연 시간을 줄일 수 있습니다.
이는 특히 전 세계적으로 분산된 사용자들에게 빠른 응답 시간을 제공하는 데 효과적입니다.
네이버가 CDN을 쓰는 것으로 알고 있습니다.
6. 데이터 압축
데이터 압축 방식을 사용하여 전송되는 데이터의 크기를 줄이면, 네트워크 대역폭을 줄일 수 있어 성능이 향상됩니다.
이는 특히 큰 파일이나 대량의 텍스트 데이터를 전송할 때 유용합니다.
7. 캐싱
HTTP 캐싱을 적절히 설정하여 자주 변경되지 않는 리소스를 클라이언트나 중간 프록시 서버에 저장해 두고, 재사용할 수 있도록 하면 성능을 크게 개선할 수 있습니다. 이를 위해 Cache-Control, ETag, Last-Modified와 같은 헤더를 활용합니다.
2. HOL Blocking에 대해서 설명해주세요.
HOL Blocking은 Head Of Line Blocking의 약자로, 큐에 있는 첫 번째 패킷이 지연되면서
뒤에 있는 다른 패킷들의 처리가 함께 지연되는 현상을 의미합니다. 이는 성능 저하를 유발할 수 있습니다.
HTTP/1.x에서는 요청과 응답이 순차적으로 처리되기 때문에 하나의 요청이 지연되면 뒤에 있는
요청도 지연될 수 있어 HOL Blocking이 발생합니다.
HTTP/2에서는 스트림(Stream)과 멀티플렉싱(Multiplexing) 개념을 도입하여 여러 요청과 응답을
동시에 처리할 수 있게 함으로써 애플리케이션 레벨에서의 HOL Blocking 문제를 해결했습니다.
이를 통해 단일 연결 내에서 여러 요청과 응답이 독립적으로 처리되어, 하나의 요청이 지연되더라도 다른
요청들이 영향을 받지 않게 됩니다.
그러나, 전송 계층에서의 HOL Blocking은 여전히 존재할 수 있습니다.
예를 들어, TCP 연결에서 패킷 손실이 발생하면 손실된 패킷을 재전송하고 그 패킷이 도착할 때까지 이후의
모든 패킷이 대기하게 되므로, 전송 계층에서 HOL Blocking이 발생할 수 있습니다.
이를 해결하기 위한 방법으로는 QUIC 프로토콜이 있습니다.
QUIC는 UDP 기반으로 설계되어 전송 계층의 HOL Blocking 문제를 해결하는 데 도움을 줍니다.
QUIC는 각 스트림이 독립적으로 처리되도록 하여 한 스트림의 손실이 다른 스트림에 영향을 미치지 않게 합니다.
3. 커넥션을 끊을 때 어떤 문제가 발생할 수 있을까요?
데이터를 입력하는 쪽에서 커넥션을 끊을 경우 문제가 있는 것으로 알고 있습니다.
만약 클라이언트가 입력 커넥션이 끊기 서버에게 요청을 보내게 되면 운영체제가 클라에게 에러 메시지를 보냅니다.
운영체제는 이것을 심각한 이슈로 판단하고 아직 receive되지 않은 데이터를 모두 삭제합니다.
비정상적인 연결 종료가 빈번하게 발생하면, 서버에서 사용 가능한 커넥션 풀의 자원이 고갈될 수 있습니다.
특히 커넥션이 끊기기 전에 자원이 제대로 반환되지 않으면, 서버의 커넥션 풀이 빠르게 소진되어 다른
클라이언트의 연결 요청을 처리하지 못할 수도 있습니다.
이러한 문제를 예방하기 위해서는 Graceful termination을 사용해야 합니다. Graceful termination은
클라이언트와 서버가 서로 통신을 종료하기 전에 데이터를 모두 안전하게 전송하고, 각 측에서 필요한 자원을
올바르게 해제하는 방법을 의미합니다.
이를 통해 데이터 손실과 자원 낭비를 방지하고, 시스템의 안정성을 유지할 수 있습니다.
'CS > Network' 카테고리의 다른 글
| SSL/TLS Handshake (0) | 2024.08.22 |
|---|---|
| HTTP 2.0 (0) | 2024.08.20 |
| TCP 제대로 이해하기 (0) | 2024.08.14 |
| 3xx - Redirection Status Code (0) | 2024.08.10 |
| 계층별 네트워크 기기 (0) | 2024.08.05 |