❐ 1. Multi-thread Step
- 앞에서 봄
❐ 2. Parallel Steps
- 앞에서 봄
❐ 3. Remote Chunk
Remote Chunk란?
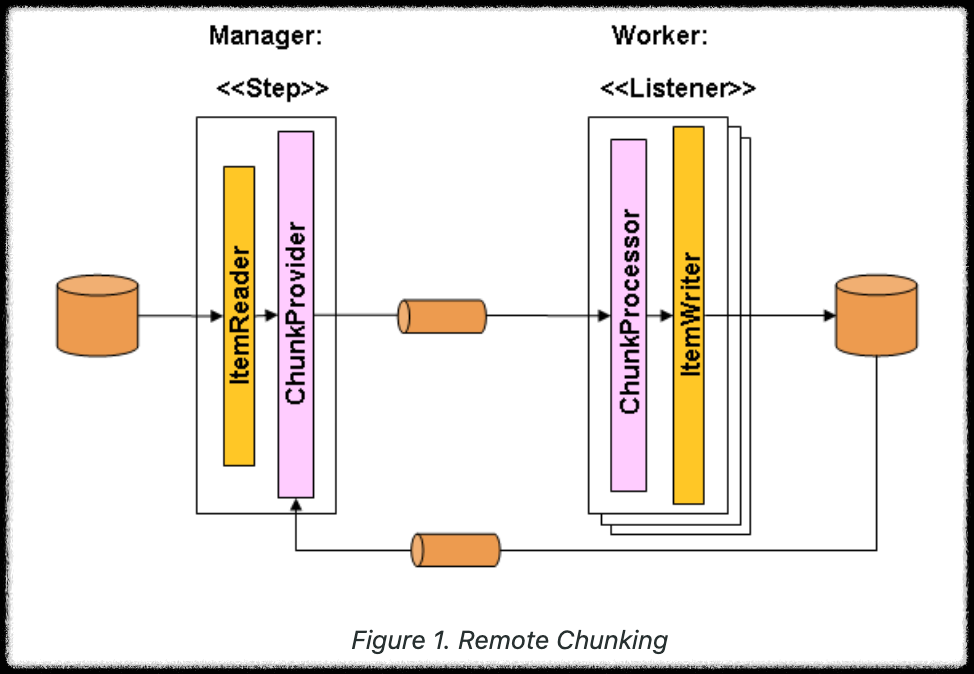
- Reader/Processor와 Writer를 서로 다른 프로세스(노드)로 분리해서 실행하는 구조
- 마스터 노드: 데이터를 읽고 나누어(Chunk 단위로) 전송
- 워커 노드: 전달받은 Chunk를 실제로 Write (DB 저장 등)
언제 효과적일까?
- Manager 컴포넌트는 하나의 프로세스로 동작하고, worker는 여러 개의 원격 프로세스로 동작함
- 이 패턴은 Manager가 병목(bottleneck)이 되지 않을 때 가장 효율적
- 따라서, 아이템을 읽는 작업보다 처리 작업이 더 비싼 경우에 특히 효과적
Manager
- Manager는 Spring Batch의 Step 구현체
- 청크(chunk) 단위의 아이템을 메시지 형태로 미들웨어(MQ 등)에 전송하는 일반화된 ItemWriter를 사용
➔ 즉, Manager는 일반적인 Step과 동일하게 동작하지만,
- ItemReader → 데이터를 읽고
- ItemProcessor → 데이터를 가공한 뒤
- ItemWriter → 직접 DB에 쓰지 않고 메시지로 전송
@Bean
fun masterStep(): Step {
return StepBuilder("masterStep", jobRepository)
.chunk<String, String>(10, txManager)
.reader(itemReader)
.processor(itemProcessor)
.writer(chunkMessageWriter) // DB X → MQ 전송
.build()
}
Worker
- Worker는 사용 중인 미들웨어(Message Broker) 에 맞는 표준 리스너(listener) 로 구현
- 예를 들어 JMS를 사용한다면, Worker는 MessageListener 구현체가 된다.
- 이들의 역할은
- 수신한 청크 데이터를 처리하는 것
- ChunkProcessor 인터페이스를 통해 표준 ItemProcessor 또는 ItemWriter를 사용하여 데이터를 처리
➔ 즉, Worker는 MQ로부터 메시지를 수신하고 그 내용을 “청크 단위로” 처리
- Manager → MQ로 Chunk 전송
- Worker → 메시지 수신 (MessageListener 역할)
- Worker 내부에서는 → ItemProcessor, ItemWriter를 사용해 데이터를 처리 (예: DB 저장)
@Component
class WorkerMessageListener(
itemWriter: ItemWriter<String>
) : MessageListener {
private val chunkProcessor: ChunkProcessor<String> =
SimpleChunkProcessor(null, itemWriter)
override fun onMessage(message: Message) {
val items: List<String> = extractItems(message)
chunkProcessor.process(items)
}
}
언제 효과적일까?
- Manager 컴포넌트는 하나의 프로세스로 동작하고, worker는 여러 개의 원격 프로세스로 동작함
- 이 패턴은 Manager가 병목(bottleneck)이 되지 않을 때 가장 효율적
- 따라서, 아이템을 읽는 작업보다 처리 작업이 더 비싼 경우에 특히 효과적
부하 분산
- 아이템들은 동적으로 분할(dynamically divided)되어 미들웨어(Message Broker) 를 통해 분산
- 따라서 모든 리스너(Worker)가 적극적으로 메시지를 소비하는(eager consumer) 방식이라면,
- 자동으로 부하 분산(load balancing)이 이루어짐
❐ 4. Partitioning
Partitioning
- Spring Batch는 Step execution을 분할해서 원격으로 실행할 수 있는 SPI도 제공
- 쉽게 말하면, Step 자체를 여러 개로 쪼개서 각각 다른 프로세스(또는 서버) 에서 실행
- SPI : Service Provider Interface
- Worker들은 별도의 Step 인스턴스로 동작
Manager가 Worker에게 보내는 메시지는 내구성(durability), 전달 보장(guaranteed delivery)이 필요하지 않음.
- 메시지를 MQ에 반드시 영구 저장할 필요가 없다는 뜻
- 왜냐하면 Worker 실행은 Spring Batch의 JobRepository 메타데이터에 의해 관리되기 때문
이해하기 쉬운 예시
➔ 회원 테이블을 ID 기준으로 4개 구간으로 나누고, 각 구간을 다른 서버가 동시에 처리하고 싶다면?
- Master
- StepPartitioner가 4개의 Partition(1~2500, 2501~5000, …) 생성
- PartitionHandler가 각 Partition을 원격 Worker로 전송
- Workers
- 각 서버에서 동일한 Step 실행 (SELECT * FROM members WHERE id BETWEEN ...)
- 각각 결과 저장
Partitioning의 핵심 SPI 구조를 구성하는 3요소 이해하기
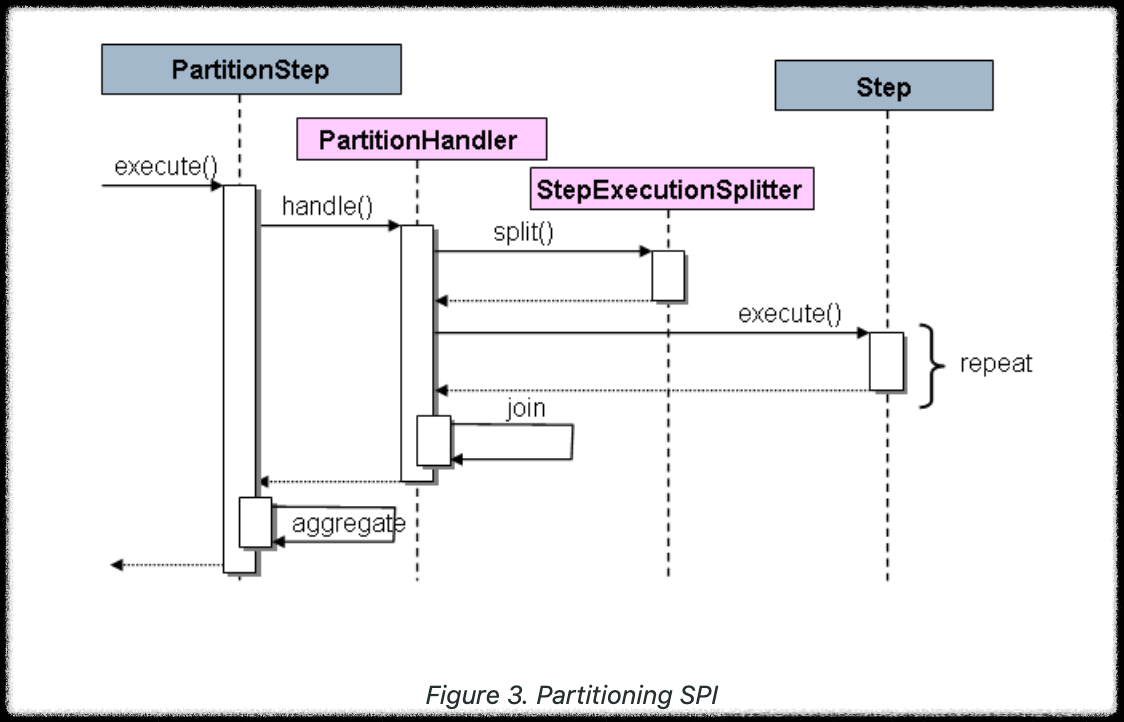
- Spring Batch의 SPI의 구성
- PartitionStep이라는 특별한 Step 구현체
- 환경에 맞게 구현해야 하는 두 개의 전략 인터페이스
- StepExecutionSplitter : Step을 여러 Partition으로 나누는 전략
- PartitionHandler : 각 Partition을 분배하고 Worker에서 실행되게 하는 전략
🌀 4-1. PartitionHandler
- Manager가 만든 각 StepExecution(파티션 단위 작업)을 실제로 Worker에게 전달하는 역할
- 멀티 스레드 방식으로 Step을 병렬 실행해주는 기본 PartitionHandler를 제공함
- 데이터를 어떻게 분할(Split) 할지, 또는 여러 Step 실행 결과를 어떻게 합칠(Aggregate) 지 알 필요 없음.
- 일반적으로 PartitionHandler는 복구(resilience) 나 장애조치(failover) 를 다룰 필요도 없음.
- 왜냐하면 이런 기능들은 대부분 사용 중인 메시징 시스템이나 그리드 플랫폼이 담당하기 때문
- 메시징이나 Worker 실패와 상관없이, 부분 재실행 가능
- JobRepository에 저장된 메타데이터를 기준으로 “어떤 파티션이 완료됐는지” 를 알고 있으므로
- PartitionHandler 인터페이스는 다양한 환경에 맞게 구현할 수 있음.
🌀 4-2. Partitioner
Partitioner란?
- 새로운 StepExecution을 실행하기 위한 ExecutionContext를 생성하는 것
- 즉, "작업을 어떻게 나눌지”만 정의
인터페이스 정의
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
// "partition1" -> { startId=1, endId=1000 }
// "partition2" -> { startId=1001, endId=2000 }- gridSize
- 나눌 파티션 개수 (예: 4개라면 4개의 StepExecution 생성)
- return Map
- key: 파티션 이름
- value: ExecutionContext (해당 파티션에서 사용할 변수들)
🌀 4-3. Binding Input Data to Steps
Partitioner가 생성한 ExecutionContext 데이터를 Step에 바인딩하는 방법
- Spring Batch에서 Partitioning을 사용할 때, 각 파티션은 서로 다른 데이터를 처리해야 함.
- 예를 들어,
- 파티션마다 다른 파일을 읽거나
- 서로 다른 ID 구간을 처리하거나
- 날짜별로 분리된 데이터를 다루거나
- 이때 핵심은 바로
- Partitioner가 생성한 ExecutionContext를 실제 Step의 Reader나 Writer에 동적으로 바인딩하는 것
- Partitioner가 만든 ExecutionContext 데이터를 @StepScope Bean과 SpEL로 런타임에 바인딩하면
하나의 Step으로 여러 파티션 데이터를 유연하게 처리할 수 있다.
'Book > Spring Batch docs' 카테고리의 다른 글
| Common Batch Patterns (0) | 2025.10.10 |
|---|---|
| Retry (0) | 2025.10.10 |
| Item processing (0) | 2025.10.09 |
| ItemReaders and ItemWriters (0) | 2025.10.07 |
| Configuring a Step (0) | 2025.10.06 |