
The Domain Language of Batch
Spring Batch의 장점
- 명확한 책임 분리(Separation of Concerns)
- 아키텍처 계층 구조의 명확한 인터페이스화
- 빠른 도입과 쉬운 사용이 가능한 기본 구현 제공
- 확장성 강화
주요 구성 요소 및 관계
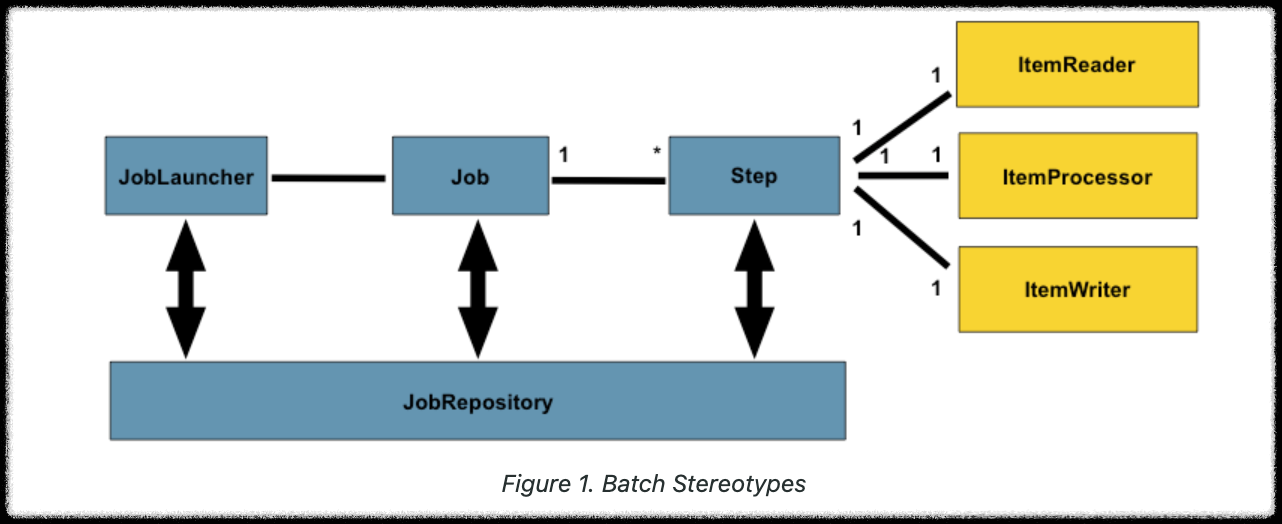
- 구성요소
- JobLauncher: Job을 시작하는 역할
- Job: 하나 이상의 Step을 가짐
- Step: 각 Step은 다음 세 가지 구성 요소(DI 기반으로 테스트와 교체가 쉬움)를 가짐
- ItemReader: 데이터를 읽음 (ex: DB, 파일 등)
- ItemProcessor: 읽은 데이터를 가공
- ItemWriter: 처리된 데이터를 출력
- JobRepository: Job의 실행 상태, 메타데이터 등을 저장
- DB에 저장되기 때문에 실패한 Job 재실행, 상태 추적등에 유리함.
- 관계
- JobLauncher → Job : 1:1 관계 (Job 하나를 실행)
- Job → Step : 1:N 관계 (Job은 여러 Step을 가질 수 있음)
- Step → ItemReader/Processor/Writer : 각각 1:1 관계
- JobRepository: 전체 Job 실행에 대한 메타데이터를 저장하는 저장소
Job
🌀Job
Job이란?
- 전체 배치 프로세스를 캡슐화하는 엔터티(entity)
- XML이나 Java 설정 파일을 통해 설정 (Job Configuration)
- 단순히 설정 객체가 아니라, 하이라키 구조의 최상위 개념
Job Hierarchy

- Job은 Step 인스턴스의 컨테이너
- 여러 개의 Step을 조합해 배치 작업 전체 흐름을 구성
- 모든 Step에 공통적인 설정들(ex. 재시작 가능 여부, 이름 등)을 Job에 설정할 수 있음.
🌀 JobInstance
JobInstance는 하나의 논리적 배치 실행 단위를 의미
예시로 이해하자.
- Job 자체는 하나 (EndOfDay라는 이름의 Job)
- 하지만 매일 실행되므로, 날마다의 실행은 각기 다른 JobInstance로 간주
- 1월 1일 실행 → JobInstance-2025-01-01
- 1월 2일 실행 → JobInstance-2025-01-02
JobInstance vs. JobExecution
- 만약 1월 1일 작업이 실패해서, 다음날 다시 실행한다면?
- 그것은 여전히 1월 1일의 JobInstance
- 이때 새롭게 생기는 것은 JobExecution입니다. (JobInstance는 동일)
- JobInstance는 "논리적 실행 단위"
- JobExecution은 "실제 실행 기록"
"데이터 로딩"은 JobInstance와 무관
- JobInstance는 데이터를 어떻게 읽을지에 대해 아무 정보도 담고 있지 않음.
- 어떤 데이터를 읽을지는 `ItemReader` 의 책임
- 예를 들어:
- EndOfDay Job을 1월1일에 실행한 경우
- ItemReader는 DB 컬럼의 `schedule_date = '2025-01-01'`인 데이터만 읽도록 구현
- 데이터 기준일을 지정하는 것은 비즈니스 규칙이며 개발자가 `ItemReader` 에서 처리해야 할 부분
"상태 복구 여부"는 JobInstance가 결정
- 같은 JobInstance로 실행할 경우
- 이전 ExecutionContext 상태를 활용할 수 있음.
- 따라서 중단된 지점부터 이어서 작업할 수 있음.
- 새로운 JobInstance로 실행할 경우
- 이전 상태는 무시되고, 처음부터 다시 처리
🌀 JobParameter
서로 다른 JobInstance는 어떻게 구분될까?
➔ 바로 `JobParameters` 로 구분
- JobParameters 객체는 배치 작업을 시작할 때 사용하는 파라미터 집합을 가지고 있음
- 이 파라미터들은
- JobInstance를 식별하는데 사용됨.
- 실행 중에 참조용(필요한) 데이터로 사용됨.

- 앞선 예시에서 1월 1일 실행과 1월 2일 실행이라는 두 개의 JobInstance가 있었음.
- 실제로 Job은 하나 뿐임.
- 단지 각각 다른 JobParameters로 실행되었을 뿐!
- 따라서, 개발자는 JobParameters로 JobInstance를 어떻게 정의할지 직접 통제할 수 있음.
근데 또 모든 JobParameters가 JobInstance를 구분하는 건 아님
val params = JobParametersBuilder()
.addString("scheduleDate", "2025-07-07", true) // 식별 기준
.addString("requestedBy", "admin", false) // 그냥 로깅용
.toJobParameters()- Spring Batch에서는 JobParameter를 넘길 때,
- 어떤 파라미터는 JobInstance를 구분하는 기준이 되고 (identifying)
- 어떤 파라미터는 단순 참고용으로만 쓰고, JobInstance를 구분하지 않게 설정할 수 있음 (non-identifying)
- 위 예제에서
- scheduleDate는 identifying parameter
- requestedBy는 non-identifying parameter
🌀 JobExecution
JobInstance : JobExecution = 1 : N
- JobExecution은 Spring Batch에서 “Job이 실제로 실행된 한 번의 시도”를 의미
- 어떤 배치 작업(Job)을 실행할 때마다 JobExecution이 하나씩 생성됨
- 실패/성공 여부와 무관하게 실행 시도마다 생성
- Job을 실행하면 그 실행이 성공하든 실패하든 매번 새로운 JobExecution이 만들어짐
- JobInstance와의 관계
- JobInstance는 논리적으로 “하나의 작업 단위”를 의미
- 예를 들어
- 매일 실행되는 EndOfDay Job이 있다면, 2017년 1월 1일의 작업이 하나의 JobInstance
- 만약 이 작업이 실패해서 다시 실행하면, JobInstance는 그대로지만 JobExecution이 하나 더 추가
- 완료의 기준
- JobInstance가 “완료”로 간주되려면, 그에 속한 JobExecution 중에서 성공적으로 끝난 것이 있어야 함.
Step
Step

- 배치 작업(Job)에서 독립적이고 순차적인 처리 단계를 나타내는 도메인 객체
- 모든 Job은 하나 이상의 Step으로만 구성
- 실제 배치 처리를 정의하고 제어하는 데 필요한 모든 정보를 담고 있음.
- Job과 마찬가지로, Step도 각각의 실행 기록(StepExecution)을 가지며, 이는 특정 JobExecution과 연결됨.
StepExcecution
- StepExecution은 Step을 한 번 실행한 시도를 의미
- Step이 실제로 실행될 때마다 새로운 StepExecution이 생성(JobExecution과 비슷)
- 하지만 만약 이전 Step이 실패했다면, 해당 Step에 대한 StepExecution은 저장되지 않음
- StepExecution에는 ExecutionContext가 포함
- 통계나 재시작에 필요한 상태 정보 등 배치 실행 간에 저장해야 할 데이터를 담을 수 있음.
- 각 실행 기록에는 아래의 데이터들이 담김
- 해당 Step
- JobExecution에 대한 참조
- 커밋/롤백 횟수
- 시작/종료 시간
- 트랜잭션
- 등등..
ExecutionContext
ExecutionContext
- Step이나 Job의 실행 상태를 저장하기 위한 key-value 저장소
- 배치 실행 도중 읽은 위치, 처리 건수 같은 중간 상태 값을 저장
- StepExecution이나 JobExecution 단위로 scope(범위)가 있음
- 데이터는 DB에 자동으로 저장되므로 재시작 시 복구가 가능
- 주의할 점
- 하나의 StepExecution에는 ExecutionContext가 딱 하나만 존재
- 모든 값은 Serializable 해야함.
예시
if (executionContext.containsKey(LINES_READ_COUNT)) {
long lineCount = executionContext.getLong(LINES_READ_COUNT);
while (reader.getPosition() < lineCount) {
record = readLine(); // 이전 줄들 skip
}
}- loadData Step 실행 중 실패 (40,321줄 처리 중 오류)
- 다음날 Job을 재실행하면:
- ExecutionContext에 저장된 LINES_READ_COUNT = 40321 사용
- 40322번째 줄부터 다시 시작함
JobRepository
JobRepository
- 지금까지 배운 모든 주요 개념들(Job, Step, Execution)의 실행 상태를 저장(persist)하는 저장소
- JobLauncher, Job, Step 등이 필요로 하는 CRUD 작업수행
- Job이 처음 실행될 때, JobExecution은 JobRepository로부터 생성
- 즉, 실행 정보를 JobRepository가 만들어서 관리하는 것
- 실행 도중에도, StepExecution과 JobExecution 객체들은 중간 상태를 계속 JobRepository에 저장
- 이게 가능한 이유가 앞에서 학습한 ExecutionContext 덕분
JobLauncher
JobLauncher
- 주어진 JobParameters(작업 매개변수)와 함께 Job(작업)을 실행하는 간단한 인터페이스
public interface JobLauncher {
public JobExecution run(
Job job,
JobParameters jobParameters
) throws JobExecutionAlreadyRunningException,
JobRestartException,
JobInstanceAlreadyCompleteException,
JobParametersInvalidException;
}
ItemReader
ItemReader
- Step에서 데이터를 한 건씩 읽는 역할을 추상화한 인터페이스
- 데이터소스에서 한 번에 하나의 아이템을 읽어옴
- 더 이상 읽을 데이터가 없으면 NULL을 반환
ItemWriter
ItemWriter
- Step에서 데이터를 일괄 저장(또는 출력)하는 역할을 추상화한 인터페이스
- 한 번에 여러 아이템을 받아 처리
- 단순히 넘겨받은 데이터를 저장하기만 하고, 그 다음 입력에 대해선 모름
- DB에 저장하거나 파일로 출력하거나 API로 전송하는데 사용됨.
ItemProcessor
ItemProcessor
- 읽어온 데이터를 가공 또는 필터링하는 역할
'Book > Spring Batch docs' 카테고리의 다른 글
| ItemReaders and ItemWriters (0) | 2025.10.07 |
|---|---|
| Configuring a Step (0) | 2025.10.06 |
| Configuring and Running a Job (0) | 2025.07.17 |
| Spring Batch Architecture (0) | 2025.07.06 |
| Spring Batch Introduction (0) | 2025.07.06 |